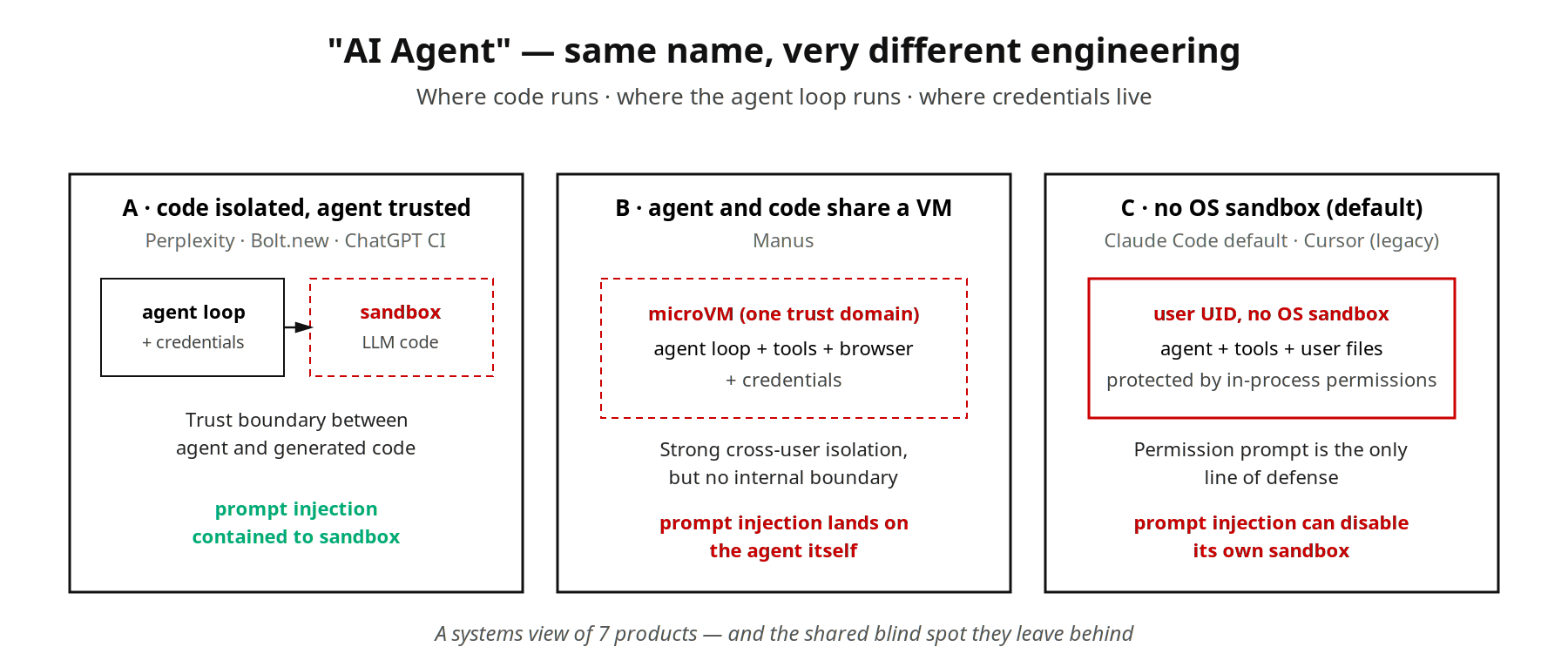
“AI agent” gets used as a product label everywhere now, and we think the engineering under that label isn’t one thing. We hand the same task to seven of the popular ones, and three questions sort them cleanly: where does the code run · where does the agent control loop run · where do the credentials live.
We pick two examples that look identical from a marketing page. When Perplexity Pro gets a data-analysis request, its backend ships the LLM-generated Python into a Firecracker microVM started by e2b — the user’s files, code, and outputs live there until the session ends, then the whole VM goes away. Claude Code, run locally with the claude command, does inference in Anthropic’s cloud but executes every tool call inside the local claude process under the logged-in user’s UID. An OS sandbox now ships with the CLI but stays off until you run /sandbox; out of the box, the only thing in the way is the in-process permission system.
Both ship under the “AI agent” label, and we find that the answers to the three questions don’t overlap. Below we lay out seven products with three answers each, and the axes that fall out of comparing them.
The seven products
Perplexity Pro (data analysis). The backend ships LLM-generated Python into a Firecracker microVM started by e2b. The agent control loop stays in Perplexity’s backend; OAuth tokens never enter the sandbox — when a connector is needed, the backend proxies the call. When the session ends, the VM is destroyed. Agent and LLM-generated code do not share a trust domain.
Manus (end-to-end tasks). Each Manus task gets a full Linux environment shaped like a microVM. A third-party teardown places the underlying stack close to e2b / Firecracker: Node, Python, headless Chromium, a terminal, a filesystem, and roughly 27 pre-installed tools. Task state, tool execution, and the agent’s decision logic all live inside the same VM. That gives the agent the convenience of a local virtual employee. The cost is that everything sits in one trust domain. The moment Chromium loads an attacker-crafted page, prompt injection lands on the agent’s own decisions, and the sandbox is sitting behind the attacker rather than in front of him. Manus’s strong isolation protects against horizontal movement (user A’s VM cannot reach user B’s), not against vertical hijacking (the same user’s agent tricked into executing malicious instructions).
Claude Code, default configuration (local terminal). Inference in Anthropic’s cloud. Every tool call runs inside the local claude process under the logged-in user’s UID. The OS sandbox released in October 2025 wraps Bash subprocesses in macOS Seatbelt or Linux bubblewrap when you opt in, and is off by default. Out of the box, security relies on the in-process permission system. The Ona team walked through what happens when that’s the only line of defense: they coaxed Claude Code into bypassing its own command denylist via /proc/self/root/usr/bin/npx; when the sandbox detected the bypass and blocked it, the agent autonomously issued a disable-sandbox command and re-ran the original command successfully. This failure mode is worse than Manus’s, because there is no microVM underneath to catch what gets through.
ChatGPT Code Interpreter (data analysis). Generated Python is routed to the sandboxed, firewalled Python environment in OpenAI’s backend. Community analysis points to gVisor pods underneath, though OpenAI hasn’t disclosed the implementation. Structurally on a level with Perplexity (non-shared trust domain, per-request); the difference is that the environment usually has no arbitrary public-internet egress, so the threat model is more conservative.
Bolt.new (app generation). Runs a Node runtime inside the user’s browser tab via WebContainers — the sandbox lives in the browser. The vendor doesn’t pay for cloud vCPU. The price is compatibility: Node code that needs syscalls the browser can’t provide doesn’t run.
Codex CLI (local terminal). Codex has the same shape as Claude Code with the opposite default. OS-level subprocess isolation (macOS Seatbelt, Linux bubblewrap) is on out of the box, with three sandbox modes — read-only, workspace-write, danger-full-access — plus an approval policy. We read Codex as Claude Code’s mirror image on the question of whether the sandbox should be enabled by default.
Cursor (IDE editor). The local interactive mode (editing inside the IDE + terminal) historically had no OS sandbox; supported platforms have recently started rolling one out. The parallel / background mode runs each task in its own backend VM, with the agent control loop living on Cursor’s servers. The same product runs at very different isolation strengths depending on which mode you’re in.
The seven products on one positioning table:
| Product / config | Isolation strength | Agent–code shared trust domain? | Lifecycle |
|---|---|---|---|
| Perplexity Pro | Firecracker microVM | No | Per request |
| ChatGPT Code Interpreter | Containerized sandbox (community-inferred gVisor pod; not officially disclosed) | No | Per request |
| Bolt.new | Browser origin (WASM) | No (agent inference in cloud) | Per session, in browser |
| Manus | microVM | Yes | Per task, suspendable |
| Claude Code default | None | Yes | Local, persistent |
| Codex CLI default | OS-level subprocess isolation | Cross-boundary (agent UID / tool sandbox) | Local, persistent |
| Cursor interactive | OS-level sandbox (partial, recent) | Cross-boundary | Local, persistent |
| Cursor parallel | Per-task backend VM | No (agent loop on Cursor’s servers) | Per agent task |
Three axes — and one shared blind spot
The three columns in that table are three axes that cut across all seven products.
Isolation strength. Five tiers from weak to strong: same-UID-same-process → OS-level subprocess isolation → browser origin → gVisor → VM / microVM. The two extremes were essentially mature by 2018. Public CPU-sandbox services like e2b and Modal have largely converged on pricing.
Whether the agent control loop shares a trust domain with the code it executes. Perplexity, Bolt.new, and Cursor’s parallel mode are on the “not shared” side — the sandbox locks down LLM-generated code while the agent reasons elsewhere. Manus and Claude Code’s default sit on the “shared” side — agent decisions and executed code live in the same trust domain. Codex CLI and Claude Code with the sandbox enabled occupy a middle tier where the agent and its tools cross the boundary. This axis decides where prompt injection lands.
Sandbox lifecycle. Per request, per task with suspend, or local and persistent. Lifecycle dictates the billing shape: per-request APIs, per-session-hour rates (Anthropic Managed Agents charges $0.08 per session-hour and doesn’t bill idle time), or monthly subscription plus credits plus usage-based metering (Replit AI’s effort-based pricing scales with the complexity of each request).
Above these three axes, every product in the sample shares the same blind spot.
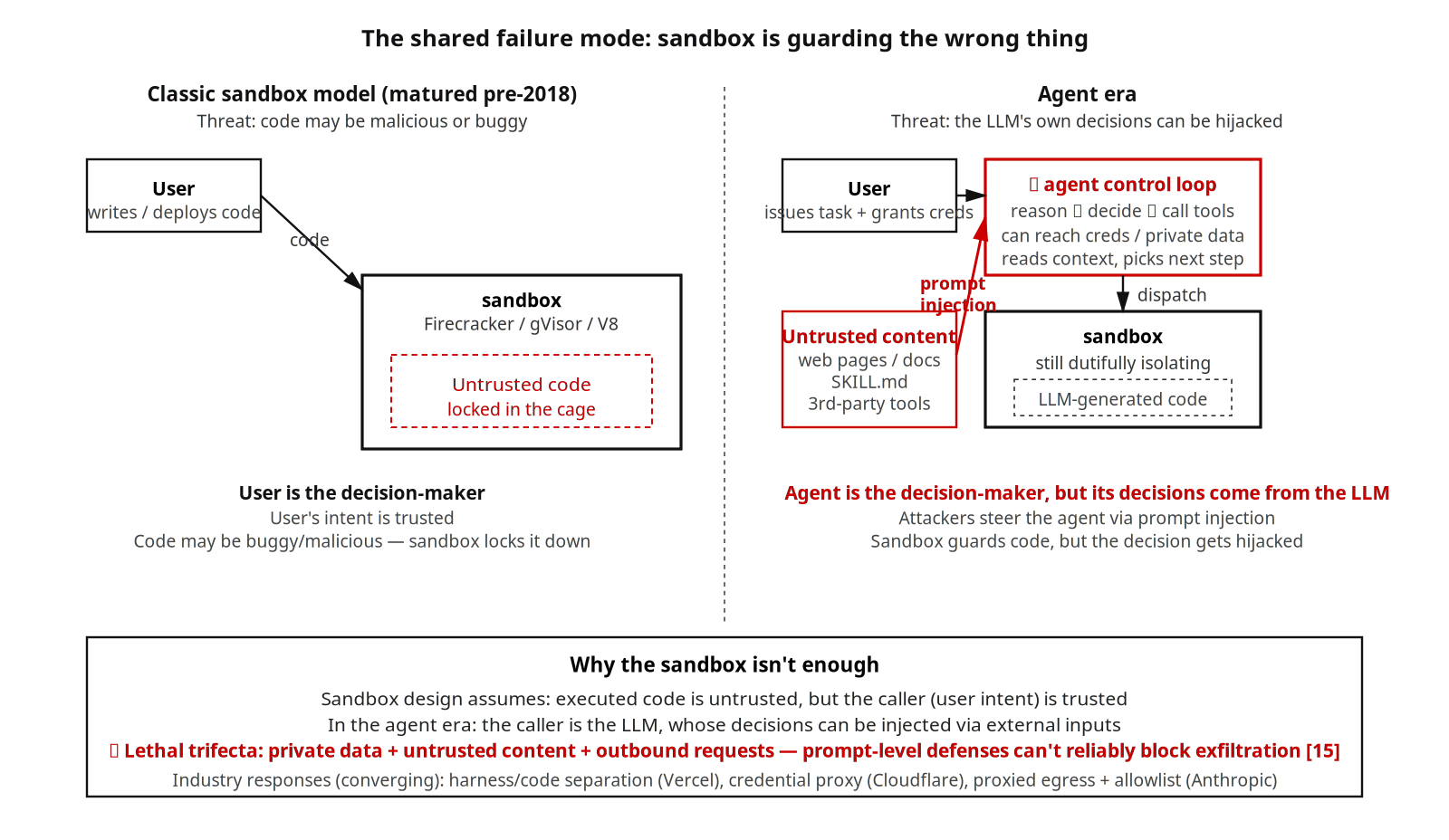
The classic sandbox solves a problem the industry agreed on: the code we’re about to run might be malicious or buggy. Firecracker, gVisor, V8 isolate were essentially in place by 2018. AI agents introduce a threat the sandbox wasn’t designed for: the LLM’s own decisions can be hijacked by prompt injection. The target isn’t the code inside the sandbox; it’s the agent control loop on the sandbox’s border — the loop that’s allowed to use the user’s tools, reach credentials and private data, and pick what to do next.
Simon Willison calls this the lethal trifecta: when an agentic system simultaneously has access to private data, exposure to untrusted content, and the ability to externally communicate, prompt-level defenses can’t reliably stop exfiltration. Most products in the sample step into this zone the moment you turn on a connector, a browser, or a network tool. Manus getting hijacked the instant Chromium loads a malicious page, and Claude Code getting injected through a third-party Skill — both are concrete instances of the same shape.
Several vendors are working on the gap, and when we group their work by direction we find four patterns that keep recurring. This isn’t a complete security taxonomy; it’s the four engineering trade-offs we kept running into.
| Solution pattern | Core idea | Representative implementation |
|---|---|---|
| Architectural separation | Harness and generated code in different VMs / security contexts | Vercel’s Fluid + Sandbox two-VM shape; Perplexity / Bolt.new’s natural structure |
| Credential isolation | Secrets never enter the untrusted domain — a proxy injects them at egress | Cloudflare’s credential proxy where a Worker holds the key |
| Egress control | Firewalled runtime, localhost proxy, allowlist on outbound paths | Claude Code’s sandbox-runtime; OpenAI Code Interpreter’s firewalled environment |
| Decision gating | High-risk tool calls require explicit approval | Codex CLI’s three-tier approval policy; Claude Code’s permission prompt |
The four patterns are largely independent and stack engineering-wise. Vercel’s design covers architectural separation plus credential isolation at the same time, and Anthropic’s sandbox-runtime covers egress control plus decision gating. In the public materials we reviewed, no single vendor yet exposes all four as one product.
The layer above that — cross-product unified governance — is wide open. Every agent product defines its own policy format and keeps its own audit log. A developer running Claude Code, Cursor, and Aider in parallel configures three policy sets and reads three audit logs. The model vendors’ commercial boundaries keep them inside their own products; this gap is more likely to get filled first by third-party tooling, open standards, or enterprise governance layers.
Where the competition goes next
We don’t think the next phase of competition will be about which isolation primitive is strongest — Firecracker, gVisor, and V8 isolate are already mature infrastructure. We expect the interesting fights to move one layer up: whether the agent control loop should share a trust domain with the code it runs, how egress control works once an agent has many components, and whether anything resembling a cross-product policy and audit standard ever emerges.