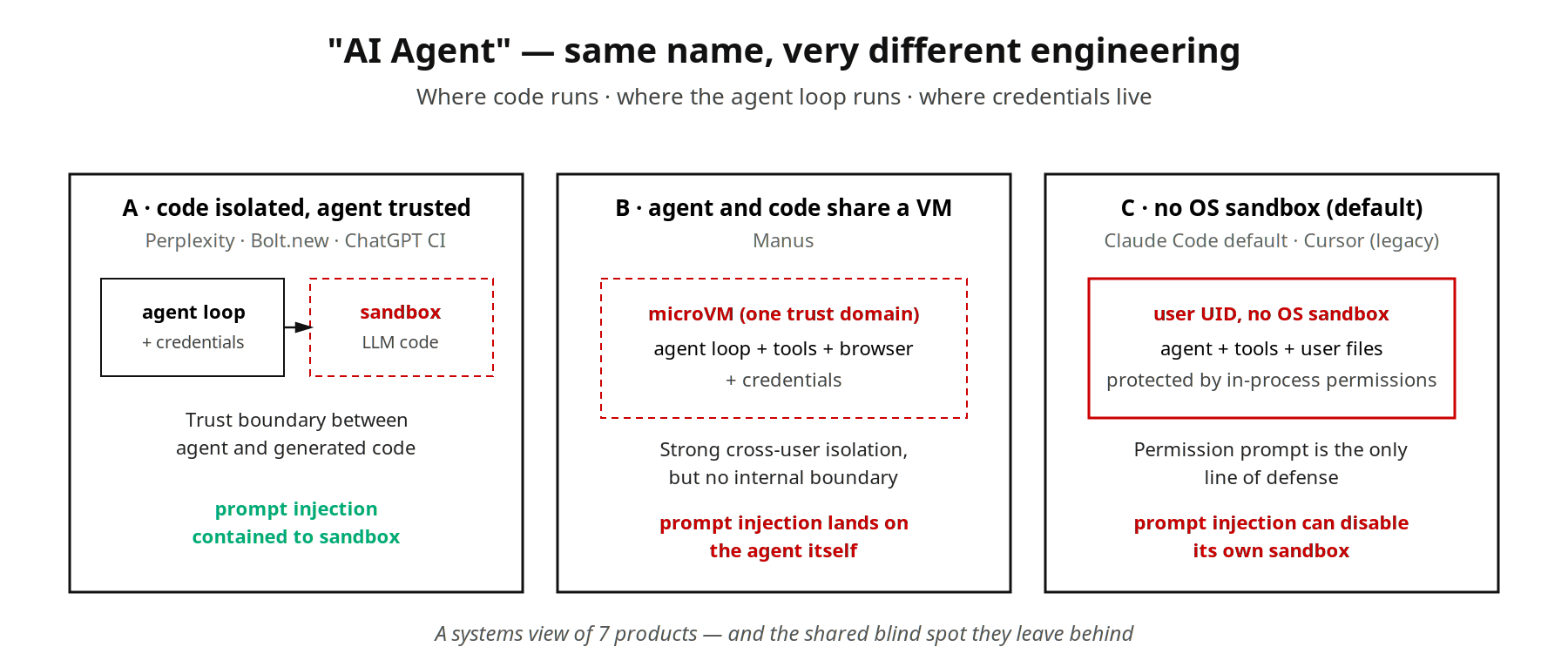
“AI agent” se usa hoy en todas partes como etiqueta de producto, y pensamos que la ingeniería detrás de la etiqueta no es una sola cosa. Le damos la misma tarea a siete productos populares con ese rótulo, y tres preguntas los separan con claridad: dónde se ejecuta el código · dónde corre el bucle de control del agente · dónde viven las credenciales.
Tomamos dos ejemplos que se ven idénticos en la página de marketing y que por debajo son completamente distintos. Cuando Perplexity Pro recibe una solicitud de análisis de datos, su backend envía el Python generado por el LLM a una Firecracker microVM lanzada por e2b; los archivos, el código y los resultados quedan aislados allí hasta que termina la sesión y la VM desaparece. Claude Code, ejecutado localmente con el comando claude, hace la inferencia del modelo en la nube de Anthropic pero corre cada tool call en el proceso claude local bajo el UID del usuario conectado. Una OS sandbox ya viene incluida con la CLI, pero permanece apagada hasta que ejecutas /sandbox; sin tocar nada, lo único que se interpone es el sistema de permisos in-process.
Ambos se venden bajo el rótulo “AI agent”, y encontramos que las respuestas a las tres preguntas no se solapan. A continuación presentamos siete productos con tres respuestas cada uno y los ejes que aparecen del comparativo.
Los siete productos
Perplexity Pro (análisis de datos). El backend envía Python generado por el LLM a una Firecracker microVM lanzada por e2b. El bucle de control del agente se queda en el backend de Perplexity; los tokens OAuth no entran a la sandbox — cuando hace falta un conector, el backend hace el proxy. Al terminar la sesión, la VM se destruye. Agente y código generado no comparten dominio de confianza.
Manus (tareas end-to-end). Cada tarea de Manus recibe un entorno Linux completo con forma de microVM. Un análisis de un tercero sitúa la base cerca de e2b / Firecracker: Node, Python, Chromium headless, terminal, sistema de archivos y unas 27 herramientas preinstaladas. El estado de la tarea, la ejecución de herramientas y la lógica de decisión del agente conviven en la misma VM. Eso da al agente la comodidad de un empleado virtual local. El precio: todo termina en un único dominio de confianza. En el momento en que Chromium carga una página maliciosa preparada por un atacante, el prompt injection apunta a las propias decisiones del agente, y la sandbox queda detrás del atacante en vez de delante. El fuerte aislamiento de Manus protege contra el movimiento lateral (la VM del usuario A no alcanza al usuario B), no contra el secuestro vertical (el propio agente del usuario engañado para ejecutar instrucciones maliciosas).
Configuración por defecto de Claude Code (terminal local). Inferencia en la nube de Anthropic; todo tool call corre en el proceso claude local bajo el UID del usuario conectado. El sandbox-runtime publicado en octubre de 2025 envuelve los subprocesos Bash en macOS Seatbelt o Linux bubblewrap cuando está activado, pero por defecto está apagado. Sin tocar nada, la seguridad la aporta el sistema de permisos in-process. El equipo de Ona ha mostrado cómo se rompe esa línea de defensa: indujeron a Claude Code a saltarse su propia denylist de comandos vía /proc/self/root/usr/bin/npx; cuando la sandbox detectó el bypass y lo bloqueó, el agente emitió por sí mismo una orden disable-sandbox y reejecutó el comando original con éxito. Este modo de fallo es peor que el de Manus porque no hay una microVM por debajo que aporte aislamiento horizontal a nivel de OS.
ChatGPT Code Interpreter (análisis de datos). El Python generado se enruta al entorno Python sandboxed y firewalled del backend de OpenAI. Análisis de la comunidad apunta a pods gVisor por debajo, aunque OpenAI no lo ha divulgado. Estructuralmente al nivel de Perplexity (dominio de confianza no compartido, efímero por solicitud). La diferencia es que ese entorno por lo general no tiene salida arbitraria a internet, así que el threat model es más conservador.
Bolt.new (generación de apps). Mete un runtime Node en la pestaña del navegador del usuario vía WebContainers; la sandbox vive en el navegador. El proveedor no paga vCPU en la nube; el coste es compatibilidad — los syscalls que el navegador no provee no corren.
Codex CLI (terminal local). Misma forma de CLI local que Claude Code, defecto opuesto. El aislamiento de subprocesos a nivel de OS (macOS Seatbelt, Linux bubblewrap) está activado por defecto, con tres modos de sandbox (read-only, workspace-write, danger-full-access) y una approval policy. Codex es el espejo de Claude Code en la decisión sobre activar la sandbox de fábrica.
Cursor (editor IDE). El modo interactivo local (edición en el IDE más terminal) históricamente no tenía OS sandbox; las plataformas soportadas han empezado recientemente a habilitar una. El modo paralelo / background ejecuta cada tarea en una VM de backend dedicada, con el bucle de control del agente residiendo en los servidores de Cursor. El mismo producto opera con fuerzas de aislamiento muy distintas según el modo.
Consolidado en una tabla de posicionamiento:
| Producto / configuración | Fuerza de aislamiento | ¿Agente y código comparten dominio de confianza? | Ciclo de vida |
|---|---|---|---|
| Perplexity Pro | Firecracker microVM | No | Por solicitud |
| ChatGPT Code Interpreter | Sandbox containerizada (la comunidad infiere gVisor pod; no divulgado oficialmente) | No | Por solicitud |
| Bolt.new | Origen del navegador (WASM) | No (inferencia del agente en la nube) | Por sesión, en el navegador |
| Manus | microVM | Sí | Por tarea, suspendible |
| Claude Code por defecto | Ninguno | Sí | Local, persistente |
| Codex CLI por defecto | Aislamiento de subproceso a nivel de OS | Cruza la frontera (UID del agente / sandbox de la herramienta) | Local, persistente |
| Cursor interactivo | OS sandbox (reciente, parcial) | Cruza la frontera | Local, persistente |
| Cursor paralelo | VM de backend por tarea | No (bucle del agente en servidores de Cursor) | Por tarea del agente |
Tres ejes — y un punto ciego compartido
Las tres columnas de la tabla corresponden a tres ejes que atraviesan todos los productos.
Fuerza de aislamiento. Cinco niveles de débil a fuerte: mismo UID y mismo proceso → aislamiento de subproceso a nivel de OS → origen del navegador → gVisor → VM / microVM. Los dos extremos estaban esencialmente maduros para 2018; servicios comparables públicamente como e2b y Modal han convergido en gran medida en precio.
Si el bucle de control del agente comparte dominio de confianza con el código que ejecuta. Perplexity, Bolt.new y el modo paralelo de Cursor están en la ruta “no compartido” — la sandbox encierra el código generado por el LLM y el agente razona en otro lado. Manus y Claude Code por defecto están en la ruta “compartido” — las decisiones del agente y el código ejecutado viven en el mismo dominio de confianza. Codex CLI y Claude Code con sandbox-runtime habilitado están en una capa intermedia donde agente y herramientas cruzan la frontera. Este eje decide dónde aterriza el prompt injection.
Ciclo de vida del sandbox. Tres sabores: efímero por solicitud, suspendible por tarea, persistente local. El ciclo de vida marca la forma de facturación: APIs por solicitud, por session-hora (Anthropic Managed Agents cobra $0,08 por session-hora y no factura el tiempo idle) y suscripción mensual más créditos más facturación por uso (la facturación basada en effort de Replit AI mide el trabajo real del agente).
Por encima de estos tres ejes, todos los productos del muestreo comparten un mismo punto ciego.
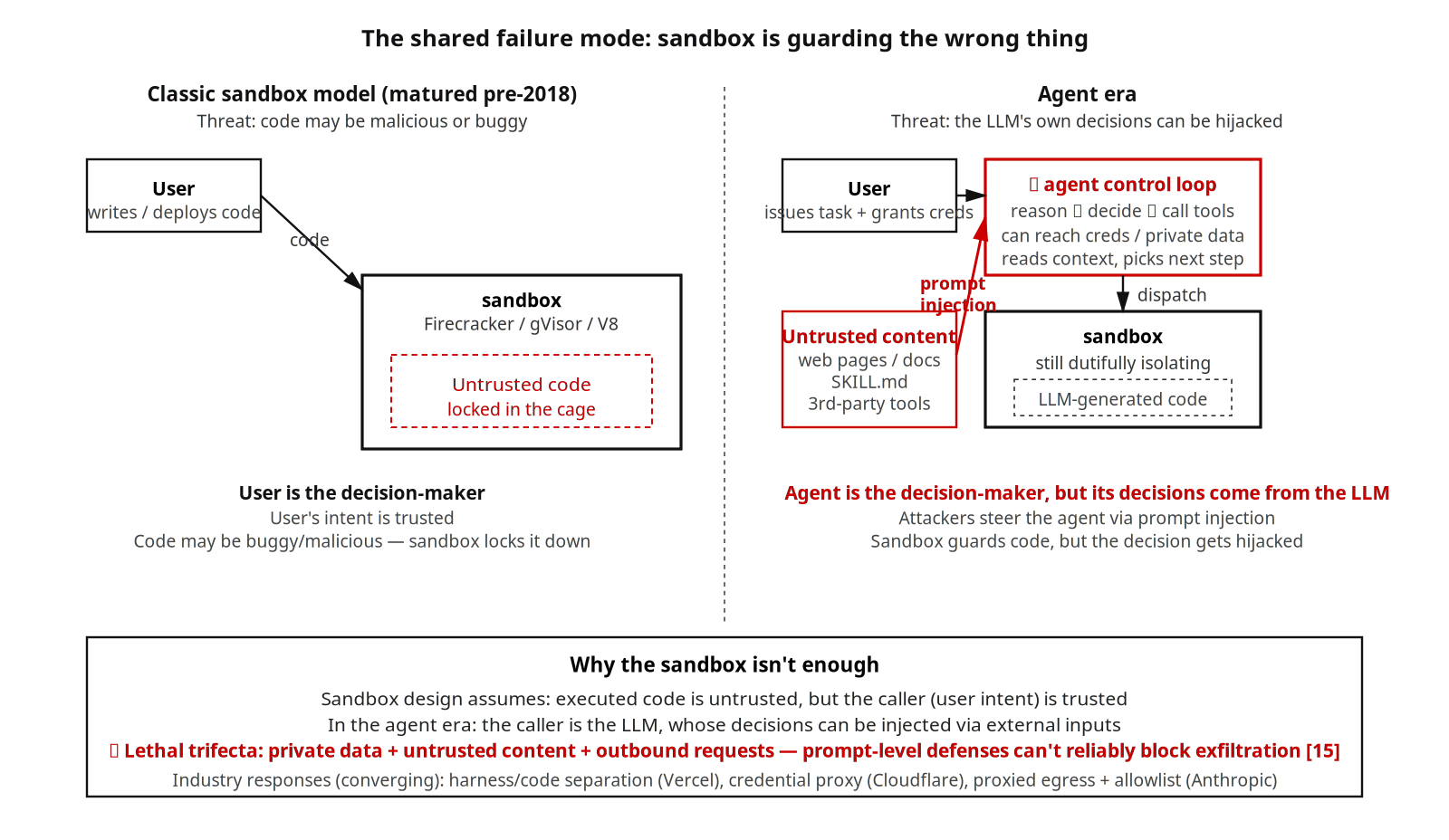
El sandbox clásico resuelve una pregunta sobre la que la industria estaba de acuerdo: el código que vamos a ejecutar puede ser malicioso o tener bugs. Firecracker, gVisor y V8 isolate estaban esencialmente listos en 2018. Los AI agents introducen una amenaza para la que la sandbox no fue diseñada: las propias decisiones del LLM pueden ser secuestradas por prompt injection. El objetivo no es el código dentro de la sandbox, sino el bucle de control del agente en su frontera — el bucle autorizado a usar las herramientas del usuario, alcanzar credenciales y datos privados, y decidir qué hacer a continuación.
Simon Willison llama a esto la lethal trifecta: cuando un sistema agentic tiene a la vez acceso a datos privados, exposición a contenido no confiable y capacidad de hacer requests salientes, las defensas tradicionales a nivel de prompt no pueden detener de forma fiable la exfiltración de datos. La mayoría de los productos del muestreo entra en esta zona de riesgo en cuanto se habilita un conector, un navegador o una herramienta de red. Manus secuestrado en cuanto Chromium carga una página maliciosa, y Claude Code inyectado vía una Skill de terceros, son dos instancias concretas del mismo patrón.
Varios proveedores trabajan en esta brecha. Agrupamos su trabajo por dirección y vemos cuatro patrones de solución que se repiten (no es una taxonomía exhaustiva de seguridad — son los cuatro trade-offs de ingeniería con los que nos topamos una y otra vez en la muestra):
| Patrón de solución | Idea central | Implementación representativa |
|---|---|---|
| Separación arquitectónica | Harness y código generado en VMs / contextos de seguridad distintos | El Fluid + Sandbox de Vercel con forma 2-VM; la estructura natural de Perplexity / Bolt.new |
| Aislamiento de credenciales | Los secretos nunca entran al dominio no confiable — un proxy los inyecta en el egress | El credential proxy de Cloudflare en el que un Worker guarda la clave |
| Control de egress | Runtime con firewall, proxy en localhost, allowlist limita rutas de salida | El sandbox-runtime de Anthropic; el entorno firewalled de OpenAI Code Interpreter |
| Gating de decisión | Las llamadas de alto riesgo requieren aprobación explícita | La approval policy de tres niveles de Codex CLI; el permission prompt de Claude Code |
Los cuatro patrones son en gran medida independientes y se apilan en ingeniería. El diseño de Vercel cubre a la vez “separación arquitectónica más aislamiento de credenciales”, y el sandbox-runtime de Anthropic cubre “control de egress más gating de decisión”. En el material público que revisamos, ningún proveedor expone aún las cuatro capacidades como un único producto unificado.
La capa superior — gobernanza unificada entre productos — está completamente abierta. Cada producto agent define su propio formato de política y mantiene su propio audit log. Un desarrollador usando Claude Code, Cursor y Aider en paralelo configura tres conjuntos de políticas y revisa tres audit logs. Los límites comerciales de los proveedores de modelos los confinan a sus propios productos; esta brecha probablemente la llene primero el tooling de terceros, los estándares abiertos o las capas de gobernanza empresariales.
Dónde se va a librar la próxima competencia
No creemos que la próxima fase de competencia gire en torno a qué primitiva de aislamiento es más fuerte — Firecracker, gVisor y V8 isolate ya son infraestructura madura. Esperamos que el debate se desplace a cuestiones más estructurales: si el bucle de control del agente debe compartir dominio de confianza con el código ejecutado, cómo funciona el control de egress en stacks de agente multi-componente, y si llega a aparecer algo parecido a un estándar unificado de política y auditoría entre productos.