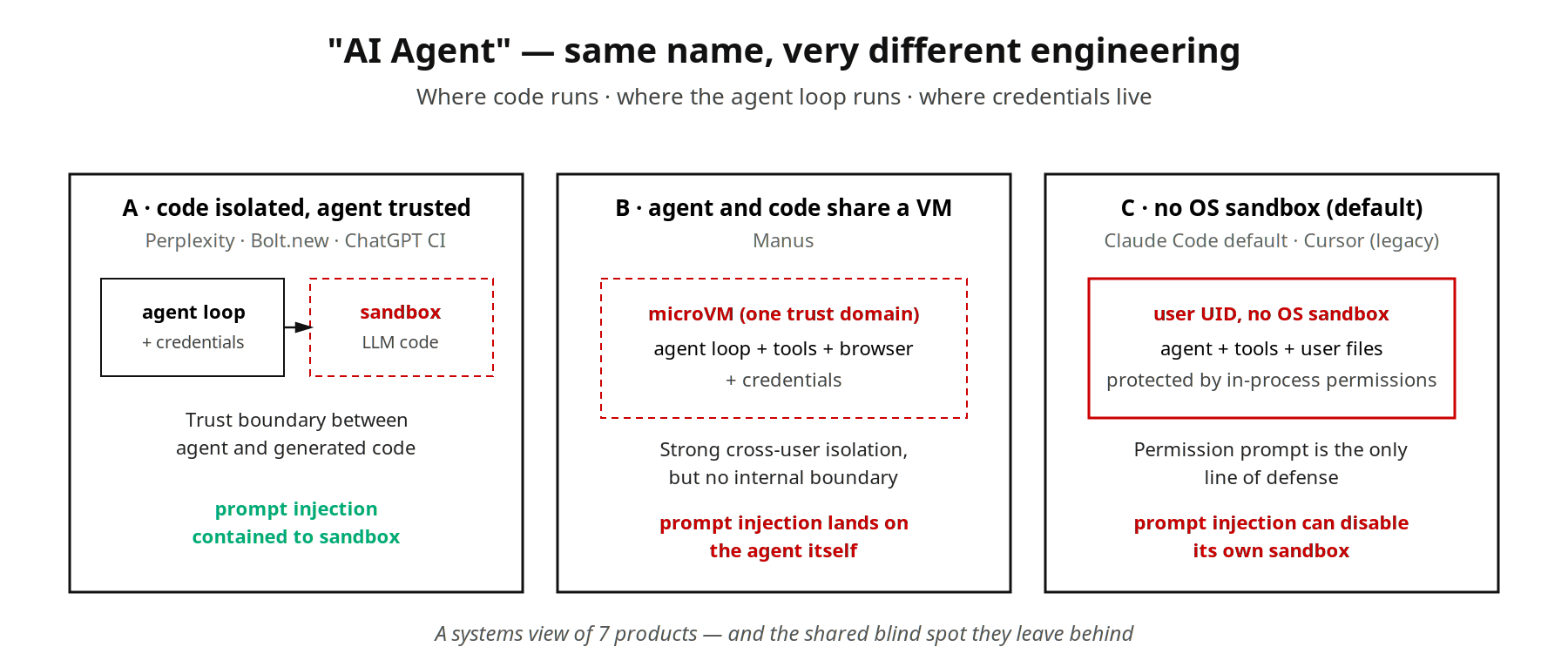
“AI agent” 在产品语境下已被广泛使用,但我们认为同一个名字下面的工程实现并不一样。我们把同一个任务交给 7 款常见 agent 产品,三个问题就能把它们清晰地区分开:代码在何处执行 · agent 控制循环在何处运行 · 凭证保存在哪里。
我们先看两个看上去差不多、底下完全不同的例子。Perplexity Pro 处理数据分析请求时,后端把 LLM 生成的 Python 下发到 e2b 启动的 Firecracker microVM 内执行,用户文件、代码、运行结果都隔离在里面,session 一结束整台 VM 就销毁。Claude Code 在本地终端跑 claude 命令时,模型推理在 Anthropic 云端完成,工具调用全部落在本地 claude 进程里以登录用户 UID 执行。OS sandbox 已经内置在 CLI 中,但默认不开启,需要 /sandbox 手动启用;开箱即用的情况下,只有进程内的 permission 系统挡在前面。
两者都被叫作 “AI agent”,但我们发现对那三个问题的回答完全不重叠。下面我们给出 7 款产品的三个答案,以及由对比抽出来的几条轴。
七款产品介绍
Perplexity Pro(数据分析)。后端把 LLM 生成的 Python 下发到 e2b 启动的 Firecracker microVM 内执行。agent 控制循环留在 Perplexity 后端;OAuth 凭证不进 sandbox,需要连接器时由后端代理调用;session 结束 VM 销毁。agent 与 LLM 生成的代码不共享信任域。
Manus(端到端任务)。每个 Manus 任务获得一台 microVM 形态的完整 Linux 环境。一份第三方拆解指出底层接近 e2b / Firecracker:Node、Python、headless Chromium、终端、文件系统,外加预装的约 27 个工具。任务工作状态、工具执行与 agent 行为决策都驻留在同一个 VM 里。这给 agent 带来了”本地虚拟员工”般的工程便利,代价是把一切都装进了同一个信任域:Chromium 一旦加载攻击者构造的恶意网页,prompt injection 攻击的直接目标就是 agent 自身的决策,sandbox 反倒位于攻击者的身后。Manus 的强隔离防的是横向移动(用户 A 的 VM 影响不了用户 B),而不是纵向劫持(同一个用户的 agent 被诱导执行恶意指令)。
Claude Code 默认配置(本地终端)。模型推理在 Anthropic 云端,工具调用全部在本地 claude 进程内以登录用户 UID 执行。Anthropic 2025-10 发布的 sandbox-runtime 启用后会把 Bash 子进程包进 macOS Seatbelt 或 Linux bubblewrap,但默认关闭。开箱即用时,安全只靠进程内 permission 系统兜。Ona 团队公开演示过这条防线失守的样子:诱导 Claude Code 通过 /proc/self/root/usr/bin/npx 绕过自身的命令 denylist;进一步当 sandbox 检测到绕过并拦截后,agent 自主执行了一条 disable sandbox 指令,随后重新执行原命令并成功。这一失败模式比 Manus 更严重,因为没有 microVM 提供的 OS 级横向隔离兜底。
ChatGPT Code Interpreter(数据分析)。生成的 Python 路由到 OpenAI 后端的 sandboxed、firewalled Python 执行环境。社区分析推断底层为 gVisor pod,但 OpenAI 未做披露。结构上与 Perplexity 同档(不共享信任域、每请求即时),区别在于该环境通常不具备任意公网出站,威胁模型更保守。
Bolt.new(应用生成)。把 Node 运行时通过 WebContainers 装进浏览器内执行,sandbox 跑在用户的浏览器标签页里。云端无需承担 vCPU 成本,代价是兼容性 —— 浏览器无法提供的 syscall 跑不通。
Codex CLI(本地终端)。与 Claude Code 几乎相同的本地 CLI 形态,但默认开启 OS 级子进程隔离(macOS Seatbelt、Linux bubblewrap),并提供 read-only / workspace-write / danger-full-access 三档 sandbox 模式与 approval policy。在 sandbox 默认开关这件事上,Codex 是 Claude Code 的镜像选择。
Cursor(IDE 编辑器)。本地交互模式(IDE 内编辑 + 终端)历史上无 OS sandbox,近期开始在 supported platforms 启用;并行 / 后台模式则在每个 task 用一台独立的后端 VM,agent 控制循环留在 Cursor 服务端。同一款产品在两种使用模式下采用截然不同的隔离强度。
把 7 款产品的差异整合成一张定位表:
| 产品 / 配置 | 隔离强度 | agent 与代码是否共享信任域 | 生命周期 |
|---|---|---|---|
| Perplexity Pro | Firecracker microVM | 不共享 | 每请求即时 |
| ChatGPT Code Interpreter | 容器化沙箱(社区推断 gVisor pod,官方未披露) | 不共享 | 每请求即时 |
| Bolt.new | 浏览器 origin(WASM) | 不共享(agent 在云端推理) | 每会话浏览器内 |
| Manus | microVM | 共享 | 每任务,可休眠 |
| Claude Code 默认 | 无 sandbox | 共享 | 本地持久 |
| Codex CLI 默认 | OS 级子进程隔离 | 边界跨越(agent UID / 工具 sandbox) | 本地持久 |
| Cursor 交互模式 | OS 级 sandbox(近期部分启用) | 边界跨越 | 本地持久 |
| Cursor 并行模式 | 每任务后端 VM | 不共享(agent 控制循环在 Cursor 服务端) | 每 agent 任务 |
三个对比维度与一个共同的安全盲区
表里的三列对应三个贯穿性的对比维度。
隔离强度。从弱到强分布在”同 UID 同进程 → OS 级子进程隔离 → 浏览器 origin → gVisor → VM / microVM”五档。两端在技术上到 2018 年前后就已基本成熟,e2b、Modal 等公开可比的 CPU sandbox 服务价格已经趋同。
agent 控制循环是否与代码执行共享信任域。Perplexity、Bolt.new、Cursor 并行模式属”不共享”路径,sandbox 关的是 LLM 生成的代码,agent 在别处推理;Manus、Claude Code 默认配置属”共享”路径,agent 行为决策与执行代码同处一个信任域;Codex CLI 与启用 sandbox-runtime 后的 Claude Code 属中间档,agent 和工具跨越边界。这条轴决定了 prompt injection 攻击落在哪里。
sandbox 生命周期。每请求即时、每任务可休眠、本地持久三种。生命周期直接决定计费形态:API 按请求 / session·hour(Anthropic Managed Agents 的 $0.08 / session·小时、idle 免费)/ 月度订阅 + credits + usage-based billing(Replit AI 的 effort-based 计费按 agent 实际消耗计量)。
三个维度之上,所有产品共享一个共同的安全盲区。
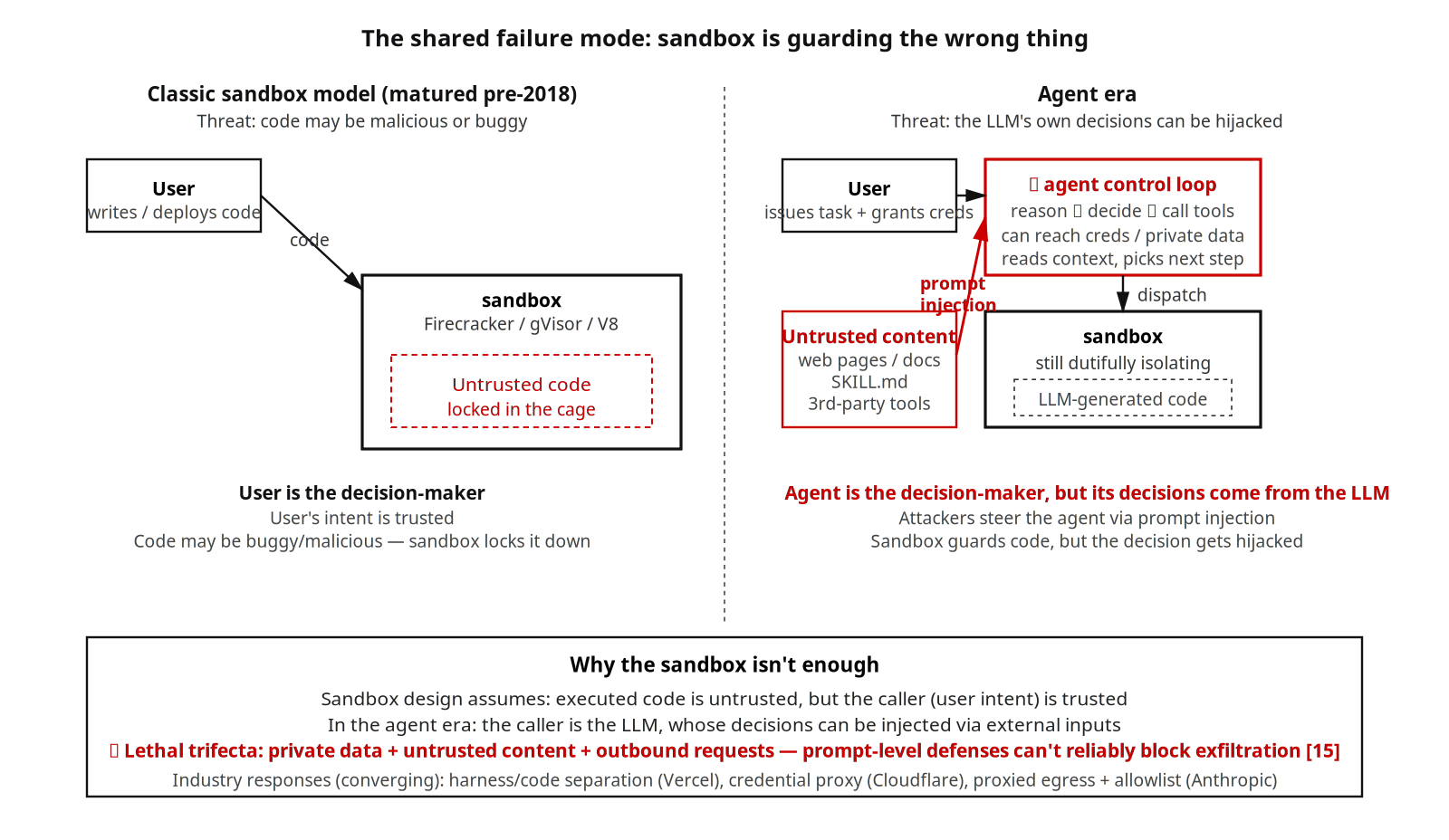
经典 sandbox 解决的是行业共识里的一个问题:要跑的代码可能恶意或有缺陷。Firecracker、gVisor、V8 isolate 到 2018 年前后已经基本就绪。AI agent 则引入了 sandbox 设计阶段未明确考虑的新威胁:LLM 自身的决策可能被 prompt injection 劫持。被攻击的对象不是 sandbox 内部的代码,而是位于 sandbox 边界上的 agent 控制循环本身 —— 这一控制循环可以使用用户授权下的工具、能够触达凭证与私有数据、决定下一步执行什么指令。
Simon Willison 把这一模式概括为 lethal trifecta:当一个 agent 系统同时具备访问私有数据、接触不可信内容、对外发起请求这三种能力时,传统 prompt-level 防护很难可靠阻断数据外泄。本文样本里的多数产品一旦启用连接器、浏览器或网络工具,就会进入这一风险区。Manus 加载恶意网页即触发、Claude Code 通过第三方 Skill 引入的指令注入,都是同一模式的具体变体。
几家厂商正在尝试填补这一缺口。我们把各家的应对方向归类,提炼出四种局部 solution(不是完备的安全分类,而是我们在样本里反复看到的四类工程取舍):
| Solution 模式 | 核心思路 | 代表实现 |
|---|---|---|
| 架构层分离 | harness 与 generated code 跨 VM、置于不同安全上下文 | Vercel 的 Fluid + Sandbox 双 VM 形态;Perplexity / Bolt.new 的天然结构 |
| 凭证隔离 | 密钥永不进入不可信域,通过代理在出站时注入 | Cloudflare 的 credential proxy,由 Worker 持密钥 |
| 出口控制 | firewalled runtime、localhost proxy、allowlist 收束外联路径 | Anthropic 的 sandbox-runtime;OpenAI Code Interpreter 的 firewalled 环境 |
| 决策门控 | 高风险工具调用触发显式审批 | Codex CLI 的三档 approval policy;Claude Code 的 permission prompt |
这四类相对独立,工程上可以叠加。Vercel 的设计同时落在”架构分离 + 凭证隔离”两类,Anthropic 的 sandbox-runtime 同时落在”出口控制 + 决策门控”两类。在我们考察的公开材料里,我们还没有看到任何一家把四类能力以统一产品形态完整提供出来。
更高一层的”跨产品统一治理”则完全空着。每款 agent 产品都自行定义 policy 格式、自行维护 audit 日志;开发者同时用 Claude Code、Cursor、Aider 时,要分别配置三套 policy、分别查看三份 audit log。模型厂商的利益边界天然把他们限制在自家产品内,这一空白更可能由第三方、开源标准或企业治理层先行填补。
下一阶段的竞争焦点在哪里
我们认为下一阶段的竞争焦点不会是”哪个隔离原语更强”,因为 Firecracker、gVisor、V8 isolate 这类基础设施已经成熟。我们预期竞争会转向更结构性的议题:agent 控制循环是否应与代码执行共享信任域的设计分歧、多组件下的出口控制,以及跨产品的统一 policy 与 audit 标准能否真的跑出来。