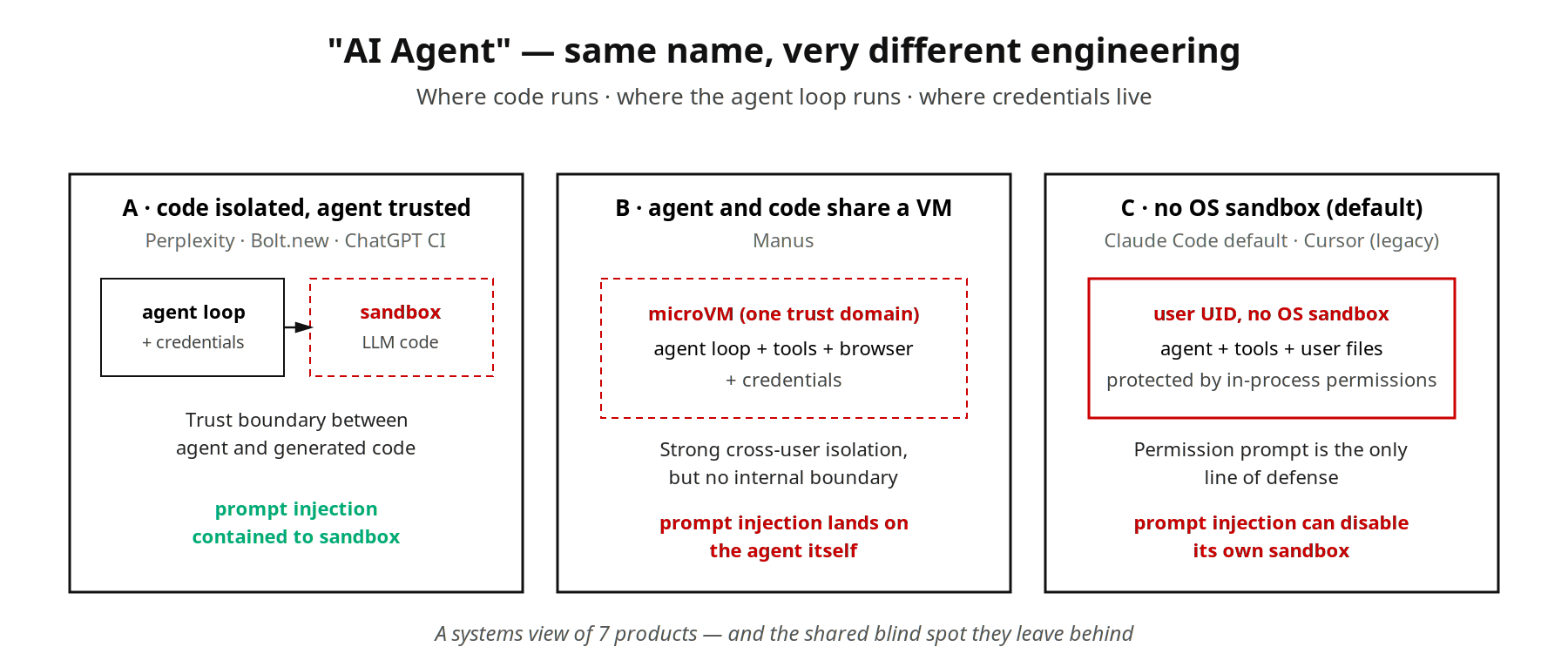
„AI agent” steht inzwischen überall als Produktbezeichnung, doch wir sehen darunter keine einheitliche Engineering-Realität. Wir geben sieben verbreiteten Produkten mit diesem Label dieselbe Aufgabe, und drei Fragen sortieren sie sauber: Wo läuft der Code · wo läuft der Agent Control Loop · wo liegen die Credentials.
Wir nehmen zwei Beispiele, die auf der Marketingseite identisch aussehen und sich darunter völlig unterscheiden. Wenn Perplexity Pro eine Datenanalyse erhält, schickt das Backend das vom LLM erzeugte Python in eine von e2b gestartete Firecracker microVM. Dateien, Code und Ergebnisse liegen dort isoliert, bis die Session endet und die VM verschwindet. Claude Code, lokal als claude aufgerufen, führt Inference in der Anthropic-Cloud aus, alle Tool Calls jedoch im lokalen claude-Prozess unter der UID des angemeldeten Nutzers. Eine OS-Sandbox gehört inzwischen zur CLI, bleibt aber aus, bis man /sandbox ausführt. Standardmäßig steht nur das prozessinterne Permission-System dazwischen.
Beide laufen unter dem Label „AI agent”, und wir stellen fest, dass sich die Antworten auf die drei Fragen nicht decken. Im Folgenden zeigen wir sieben Produkte mit je drei Antworten und die Achsen, die aus dem Vergleich fallen.
Die sieben Produkte
Perplexity Pro (Datenanalyse). Das Backend schickt LLM-generiertes Python in eine von e2b gestartete Firecracker microVM. Der Agent Control Loop bleibt im Perplexity-Backend; OAuth-Tokens betreten die Sandbox nie — wird ein Connector gebraucht, proxyt das Backend den Aufruf. Session-Ende, VM weg. Agent und LLM-generierter Code teilen keine Trust Domain.
Manus (End-to-End-Aufgaben). Jede Manus-Aufgabe erhält eine vollständige Linux-Umgebung in microVM-Form. Eine Third-Party-Analyse verortet den Unterbau nahe an e2b / Firecracker: Node, Python, headless Chromium, Terminal, Dateisystem und rund 27 vorinstallierte Tools. Arbeitsstand, Tool-Ausführung und Agent-Entscheidungslogik leben in derselben VM. Das gibt dem Agent den Komfort eines lokalen virtuellen Mitarbeiters. Der Preis: alles sitzt in einer Trust Domain. Sobald Chromium eine vom Angreifer präparierte Seite lädt, zielt Prompt Injection direkt auf die Entscheidungen des Agents, und die Sandbox steht hinter dem Angreifer statt davor. Die starke Isolation von Manus schützt gegen laterale Bewegung (die VM von Nutzer A erreicht nicht Nutzer B), nicht gegen vertikale Übernahme (der Agent desselben Nutzers wird zu bösartiger Ausführung verleitet).
Claude Code Standardkonfiguration (lokales Terminal). Inference in der Anthropic-Cloud; jeder Tool Call läuft im lokalen claude-Prozess unter der UID des Nutzers. Die im Oktober 2025 veröffentlichte sandbox-runtime kapselt Bash-Subprozesse in macOS Seatbelt oder Linux bubblewrap, wenn man sie einschaltet — standardmäßig ist sie aus. Ohne Eingriff bleibt nur das prozessinterne Permission-System. Das Ona-Team hat öffentlich gezeigt, wie diese Verteidigungslinie reißt: Claude Code wurde verleitet, die eigene Command-Denylist via /proc/self/root/usr/bin/npx zu umgehen; als die Sandbox die Umgehung erkannte und blockierte, gab der Agent eigenständig ein disable-sandbox-Kommando aus und führte das Originalkommando erneut erfolgreich aus. Dieser Failure Mode ist schlimmer als bei Manus, weil keine microVM darunter horizontale OS-Isolation absichert.
ChatGPT Code Interpreter (Datenanalyse). Generiertes Python wird in OpenAIs sandboxed und firewalled Python-Execution-Umgebung im Backend geroutet. Community-Analysen vermuten gVisor-Pods im Unterbau; OpenAI hat das nicht offengelegt. Strukturell auf einer Linie mit Perplexity (keine geteilte Trust Domain, per-Request flüchtig). Der Unterschied: diese Umgebung hat üblicherweise keinen beliebigen öffentlichen Internet-Egress, das Threat Model ist konservativer.
Bolt.new (App-Generierung). Bringt eine Node-Runtime via WebContainers in den Browser-Tab des Nutzers — die Sandbox läuft im Browser. Cloud-vCPU-Kosten entfallen; der Preis ist Kompatibilität. Syscalls, die der Browser nicht liefert, laufen nicht.
Codex CLI (lokales Terminal). Dieselbe lokale CLI-Form wie Claude Code, mit umgekehrter Voreinstellung. OS-level Subprocess-Isolation (macOS Seatbelt, Linux bubblewrap) ist standardmäßig an, mit drei Sandbox-Modi (read-only, workspace-write, danger-full-access) und einer Approval Policy. Codex ist beim Sandbox-Default das Spiegelbild von Claude Code.
Cursor (IDE-Editor). Der lokale interaktive Modus (Editieren in der IDE plus Terminal) hatte historisch keine OS-Sandbox; auf supported Platforms wird sie inzwischen schrittweise ausgerollt. Der Parallel- / Background-Modus betreibt jede Aufgabe in einer eigenen Backend-VM, der Agent Control Loop bleibt auf Cursors Servern. Dasselbe Produkt fährt je nach Modus völlig unterschiedliche Isolationsstärken.
Zusammengefasst in einer Positionierungstabelle:
| Produkt / Config | Isolationsstärke | Agent & Code geteilte Trust Domain? | Lifecycle |
|---|---|---|---|
| Perplexity Pro | Firecracker microVM | Nein | Per-Request |
| ChatGPT Code Interpreter | Containerisierte Sandbox (Community vermutet gVisor-Pod; offiziell nicht offengelegt) | Nein | Per-Request |
| Bolt.new | Browser Origin (WASM) | Nein (Agent-Inference in Cloud) | Per Session, im Browser |
| Manus | microVM | Ja | Per Task, suspendierbar |
| Claude Code Default | Keine | Ja | Lokal, persistent |
| Codex CLI Default | OS-Subprocess-Isolation | Grenzübergreifend (Agent-UID / Tool-Sandbox) | Lokal, persistent |
| Cursor interaktiv | OS-Sandbox (jüngst partiell) | Grenzübergreifend | Lokal, persistent |
| Cursor parallel | Backend-VM pro Task | Nein (Agent-Loop auf Cursor-Servern) | Per Agent-Task |
Drei Achsen — und ein gemeinsamer blinder Fleck
Die drei Spalten der Tabelle entsprechen drei Achsen, die alle Produkte durchziehen.
Isolationsstärke. Fünf Stufen von schwach bis stark: same-UID same-process → OS-Subprocess-Isolation → Browser Origin → gVisor → VM / microVM. Die beiden Extreme waren bis 2018 im Wesentlichen ausgereift; vergleichbare öffentliche CPU-Sandbox-Dienste wie e2b und Modal haben sich preislich weitgehend angeglichen.
Teilt der Agent Control Loop eine Trust Domain mit ausgeführtem Code? Perplexity, Bolt.new und Cursors Parallel-Modus liegen auf dem „nicht geteilten” Pfad — die Sandbox sperrt LLM-generierten Code ein, der Agent denkt anderswo. Manus und Claude Code Default liegen auf dem „geteilten” Pfad — Agent-Entscheidungen und ausgeführter Code sitzen in derselben Trust Domain. Codex CLI und Claude Code mit aktivierter sandbox-runtime liegen in einer mittleren „grenzübergreifenden” Stufe, in der Agent und Tools die Grenze überschreiten. Diese Achse entscheidet, wo Prompt Injection landet.
Sandbox-Lifecycle. Drei Varianten: per-Request flüchtig, per-Task suspendierbar, lokal persistent. Der Lifecycle treibt die Abrechnungsform: per-Request-APIs, per-Session-Hour (Anthropic Managed Agents nimmt $0.08 pro Session-Stunde und rechnet Idle-Zeit nicht ab) und monatliches Abo plus Credits plus Usage-based Billing (Replit AIs effort-based Billing misst die tatsächliche Agent-Arbeit).
Über diesen drei Achsen teilen sich alle Produkte im Sample denselben blinden Fleck.
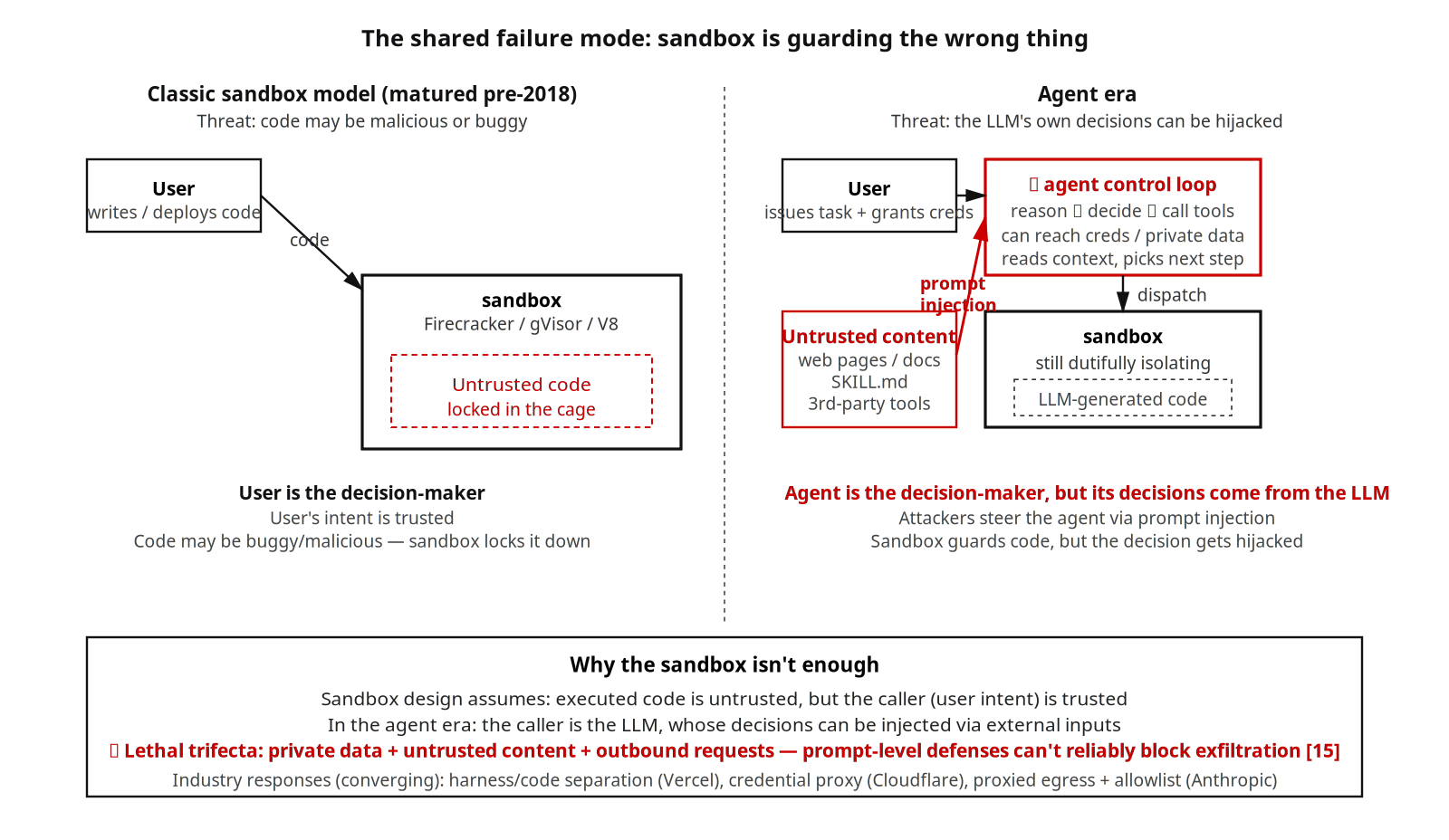
Die klassische Sandbox löst eine Frage, auf die sich die Branche geeinigt hat: der gleich auszuführende Code könnte bösartig oder buggy sein. Firecracker, gVisor, V8 isolate waren bis 2018 weitgehend bereit. AI Agents bringen eine Bedrohung mit, für die die Sandbox nicht designt wurde: die Entscheidungen des LLM selbst können per Prompt Injection gekapert werden. Ziel ist nicht der Code in der Sandbox, sondern der Agent Control Loop an deren Grenze — der Loop, der die User-Tools nutzen darf, an Credentials und private Daten reicht und den nächsten Schritt wählt.
Simon Willison nennt das die lethal trifecta: hat ein Agentic System gleichzeitig Zugriff auf private Daten, Berührung mit untrusted Content und die Fähigkeit zu Outbound-Requests, können klassische Prompt-Level-Defenses Datenabfluss nicht zuverlässig stoppen. Die meisten Produkte im Sample betreten diese Risikozone, sobald ein Connector, Browser oder Network-Tool aktiv ist. Manus wird beim Laden einer bösartigen Seite gekapert, Claude Code per Third-Party-Skill injiziert — zwei konkrete Varianten desselben Musters.
Mehrere Anbieter arbeiten an dieser Lücke. Wir gruppieren ihre Arbeit nach Richtung und sehen vier wiederkehrende Lösungsmuster (keine vollständige Sicherheitstaxonomie — sondern die vier Engineering-Trade-offs, die uns im Sample immer wieder begegnet sind):
| Solution-Muster | Kernidee | Repräsentative Umsetzung |
|---|---|---|
| Architektur-Trennung | Harness und Generated Code in verschiedenen VMs / Sicherheitskontexten | Vercels Fluid + Sandbox 2-VM-Form; die natürliche Struktur von Perplexity / Bolt.new |
| Credential-Isolation | Secrets betreten die Untrusted Domain nie — ein Proxy injiziert sie beim Egress | Cloudflares credential proxy, bei dem ein Worker den Key hält |
| Egress-Kontrolle | Firewalled Runtime, Localhost-Proxy, Allowlist begrenzt Outbound-Pfade | Anthropics sandbox-runtime; OpenAI Code Interpreters firewalled Umgebung |
| Decision Gating | High-Risk Tool Calls erzwingen explizite Approval | Codex CLIs dreistufige Approval Policy; Claude Codes Permission Prompt |
Die vier Muster sind weitgehend unabhängig und engineering-seitig stapelbar. Vercels Design deckt „Architektur-Trennung plus Credential-Isolation” gleichzeitig ab, und Anthropics sandbox-runtime deckt „Egress-Kontrolle plus Decision Gating” ab. In dem von uns gesichteten öffentlichen Material exponiert noch kein Anbieter alle vier Fähigkeiten als ein einheitliches Produkt.
Die Schicht darüber — produktübergreifende einheitliche Governance — ist weit offen. Jedes Agent-Produkt definiert sein eigenes Policy-Format und führt eigene Audit-Logs. Wer Claude Code, Cursor und Aider parallel nutzt, pflegt drei Policy-Sätze und prüft drei Audit-Logs. Die kommerziellen Grenzen der Model-Vendors halten sie in ihren Produkten; diese Lücke wird wahrscheinlich zuerst durch Third-Party-Tools, Open Standards oder Enterprise-Governance-Layer gefüllt.
Wo der nächste Wettbewerb stattfindet
Wir glauben nicht, dass der nächste Wettbewerb ein Vergleich darüber sein wird, welches einzelne Isolations-Primitiv stärker ist — Firecracker, gVisor und V8 isolate sind reife Infrastruktur. Wir erwarten, dass sich der Wettbewerb auf strukturellere Fragen verlagert: ob der Agent Control Loop eine Trust Domain mit ausgeführtem Code teilen sollte, wie Egress-Kontrolle über Multi-Komponenten-Agent-Stacks funktioniert, und ob sich produktübergreifende Policy- und Audit-Standards überhaupt etablieren.