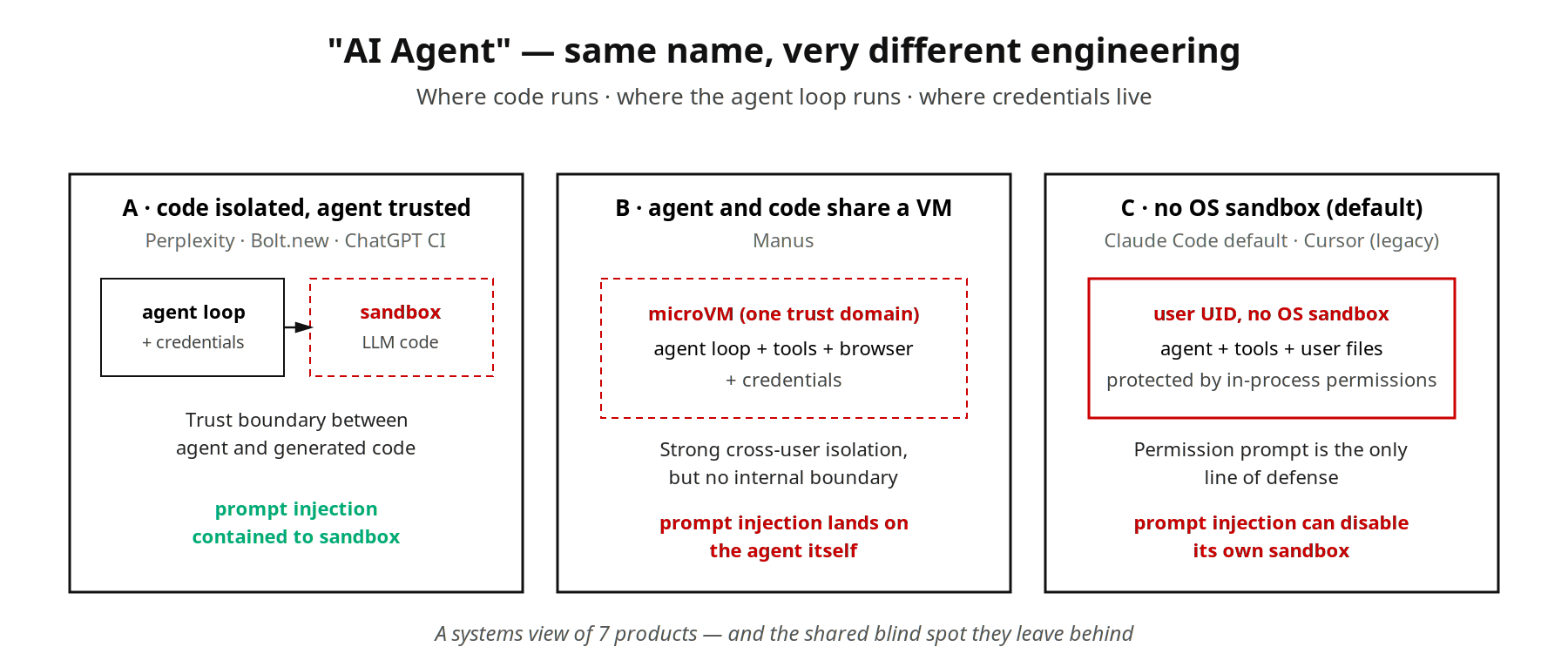
「AI agent」は製品ラベルとして広く使われているが、私たちの見るところ、その下の工学的実装は揃っていない。私たちは同じタスクを 7 製品に渡し、3 つの問いで仕分けてみる:コードはどこで実行されるか・agent の制御ループはどこで動くか・認証情報はどこに置かれるか。3 つの問いで違いははっきりする。
まずはマーケティングページ上は同じに見えて、中身が完全に違う 2 例を取り上げる。Perplexity Pro はデータ分析リクエストを処理する際、バックエンドが LLM 生成の Python を e2b が起動した Firecracker microVM 内に投入する。ユーザーのファイル・コード・実行結果はそこに隔離され、session 終了で VM ごと破棄される。Claude Code はローカル端末で claude コマンドとして動く。モデル推論は Anthropic クラウドで行われるが、ツール呼び出しはすべてローカルの claude プロセス内でログインユーザーの UID として実行される。OS sandbox は CLI に同梱されているが、デフォルトでは無効で、/sandbox で明示的に有効化する必要がある。何もしなければ、前面に立つのはプロセス内の permission システムだけだ。
両者とも「AI agent」というラベルで売られているが、私たちが確かめると 3 つの問いへの答えはまったく重ならない。以下では 7 製品の 3 つずつの答えと、比較から浮かぶいくつかの軸を順に見ていく。
7 つの製品
Perplexity Pro(データ分析)。バックエンドが LLM 生成の Python を e2b 起動の Firecracker microVM に投入して実行する。agent の制御ループは Perplexity のバックエンドに残る。OAuth トークンは sandbox に入らず、コネクタが必要な場合はバックエンド側でプロキシして呼び出す。session 終了で VM は破棄される。agent と LLM 生成コードは信頼ドメインを共有しない。
Manus(エンドツーエンドのタスク実行)。Manus の各タスクは microVM 形態の完全な Linux 環境を 1 台得る。第三者の解析によれば基盤は e2b / Firecracker に近い。Node、Python、headless Chromium、ターミナル、ファイルシステム、約 27 種の事前インストールされたツールを含む。タスクの作業状態・ツール実行・agent の意思決定がすべて同じ VM 内に置かれる。これは agent に「ローカルの仮想従業員」のような工学的便利さを与えるが、代償としてすべてが同一の信頼ドメインに収まる。Chromium が攻撃者の悪意あるページを読み込めば、prompt injection のターゲットは agent 自身の意思決定になり、sandbox は攻撃者の後ろに位置する。Manus の強い隔離が防ぐのは水平移動(ユーザー A の VM がユーザー B に影響しない)であり、縦方向の乗っ取り(同じユーザーの agent が悪意ある指示を実行させられる)ではない。
Claude Code のデフォルト設定(ローカル端末)。モデル推論は Anthropic クラウド、ツール呼び出しはすべてローカルの claude プロセス内でログインユーザーの UID として実行される。Anthropic が 2025-10 に公開した sandbox-runtime は、有効化すると Bash 子プロセスを macOS Seatbelt あるいは Linux bubblewrap に包むが、デフォルトでは無効。素の状態では、安全性はプロセス内 permission に委ねられる。Ona チームはこの防御線が崩れる様子を公開実証している:Claude Code を /proc/self/root/usr/bin/npx 経由で自身の denylist 回避に誘導し、sandbox が回避を検知してブロックすると、agent 自身が disable sandbox 指示を出して元のコマンドを再実行・成功させた。この失敗モードは Manus より深刻だ。microVM による OS レベルの水平隔離の下支えがないためだ。
ChatGPT Code Interpreter(データ分析)。生成された Python は OpenAI バックエンドの sandboxed・firewalled な Python 実行環境にルーティングされる。コミュニティ分析では基盤を gVisor pod と推定するが、OpenAI は明示していない。構造的には Perplexity と同档(信頼ドメインを共有しない・リクエスト単位で即時破棄)。違いは、この環境が一般に任意の公衆網への egress を持たず、脅威モデルがより保守的である点。
Bolt.new(アプリ生成)。Node ランタイムを WebContainers でブラウザ内に詰め込み、sandbox はユーザーのブラウザタブで動作する。クラウド側で vCPU コストを負担しない代わりに、互換性が代償になる。ブラウザが提供できない syscall は通らない。
Codex CLI(ローカル端末)。Claude Code とほぼ同じローカル CLI 形態だが、OS レベルのサブプロセス隔離(macOS Seatbelt、Linux bubblewrap)がデフォルトで有効。read-only / workspace-write / danger-full-access の 3 段階の sandbox モードと approval policy を提供する。sandbox を素のままで有効にしておくかどうかという問いで、Codex は Claude Code の鏡像となる選択をしている。
Cursor(IDE エディタ)。ローカル対話モード(IDE 内編集 + ターミナル)はもともと OS sandbox を持たなかったが、supported platforms で最近段階的に有効化が始まった。並列・バックグラウンドモードでは各タスクに独立したバックエンド VM を割り当て、agent の制御ループは Cursor のサーバ側に残る。同じ製品でも 2 つの利用モードで隔離強度はまったく異なる。
7 製品の差異を 1 枚の位置付け表に統合する:
| 製品 / 設定 | 隔離強度 | agent とコードは信頼ドメインを共有するか | ライフサイクル |
|---|---|---|---|
| Perplexity Pro | Firecracker microVM | 共有しない | リクエスト毎 |
| ChatGPT Code Interpreter | コンテナ化サンドボックス(コミュニティ推測の gVisor pod、公式非公表) | 共有しない | リクエスト毎 |
| Bolt.new | ブラウザ origin(WASM) | 共有しない(agent はクラウドで推論) | session 毎・ブラウザ内 |
| Manus | microVM | 共有 | タスク毎・休止可 |
| Claude Code デフォルト | sandbox なし | 共有 | ローカル永続 |
| Codex CLI デフォルト | OS レベルのサブプロセス隔離 | 境界跨ぎ(agent UID / ツール sandbox) | ローカル永続 |
| Cursor 対話モード | OS レベル sandbox(最近部分的に有効化) | 境界跨ぎ | ローカル永続 |
| Cursor 並列モード | タスク毎のバックエンド VM | 共有しない(agent 制御ループは Cursor サーバ側) | agent タスク毎 |
3 つの軸と共通の盲点
表の 3 列は、全製品を貫く 3 つの比較軸に対応する。
隔離強度。弱から強へ「同 UID 同プロセス → OS レベルのサブプロセス隔離 → ブラウザ origin → gVisor → VM / microVM」の 5 段階に分布する。両端は技術的には 2018 年前後にほぼ成熟しており、e2b、Modal などの公開比較可能な CPU sandbox サービスの価格も収束している。
agent 制御ループはコード実行と信頼ドメインを共有するか。Perplexity、Bolt.new、Cursor 並列モードは「共有しない」経路。sandbox が閉じ込めるのは LLM 生成コードで、agent は別の場所で推論する。Manus と Claude Code デフォルト設定は「共有」経路。agent の意思決定と実行コードが同じ信頼ドメインに同居する。Codex CLI と sandbox-runtime を有効にした Claude Code は中間で、agent とツールが境界を跨ぐ。この軸が prompt injection の落ちる場所を決める。
sandbox のライフサイクル。リクエスト毎即時・タスク毎で休止可・ローカル永続の 3 種。ライフサイクルは課金形態を直接決める。リクエスト課金 API、session·時間課金(Anthropic Managed Agents の $0.08 / session·時間、idle は無料)、月額サブスクリプション + クレジット + 使用量課金(Replit AI の effort-based 課金は agent の実消費を計量する)。
3 つの軸の上で、すべての製品が共通の盲点を抱えている。
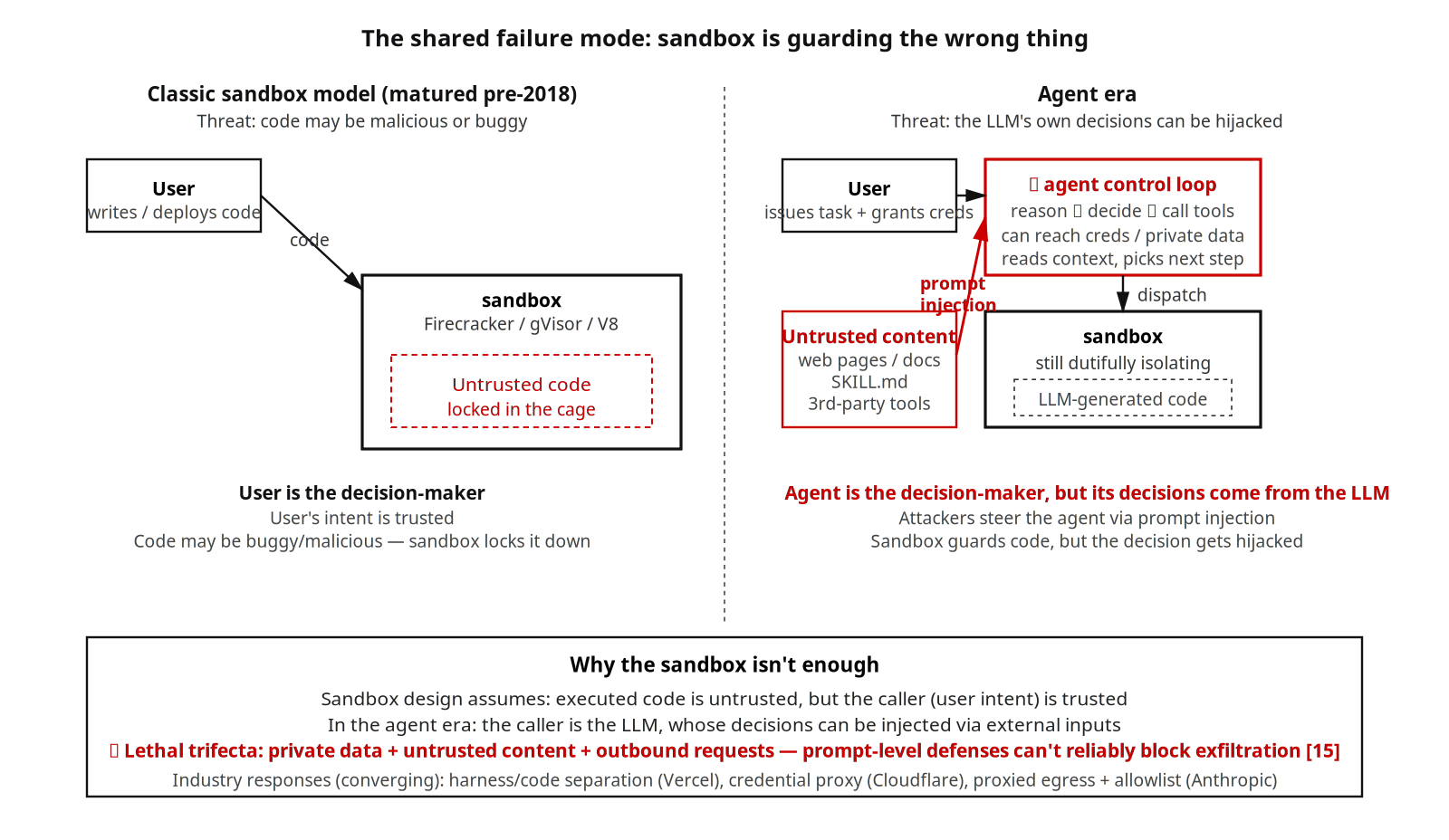
古典的な sandbox は業界共通の課題に答えを出す。実行されるコードは悪意があるか不具合があるかもしれない、というものだ。Firecracker、gVisor、V8 isolate は 2018 年前後に基本的に整っていた。AI agent は sandbox の設計段階で明確に想定されなかった新しい脅威を持ち込んだ:LLM 自身の意思決定が prompt injection で乗っ取られ得る。攻撃対象は sandbox 内のコードではなく、sandbox の境界にある agent 制御ループそのもの。この agent はユーザー認可のツールを使え、認証情報や私的データに到達でき、次に実行する指示を決定する。
Simon Willison はこのモデルを lethal trifecta とまとめている。agent システムが私的データへのアクセス・信頼できない内容への露出・対外リクエストの実行の 3 つを同時に持つとき、従来の prompt レベルの防御ではデータ漏えいを確実には止められない。本稿のサンプル中の多くの製品は、コネクタ・ブラウザ・ネットワークツールを有効にした時点でこのリスク領域に入る。Manus が悪意あるページを読み込んだ瞬間に発動するケース、Claude Code が第三者 Skill 経由で指示注入されるケースは、同じパターンの具体的な変種だ。
複数のベンダーがこのギャップを埋めようとしている。私たちは各社の対応方向を分類し、4 つの局所的 solution に整理した(網羅的なセキュリティ分類ではなく、私たちがサンプルの中で繰り返し見た 4 つの工学的トレードオフだ):
| Solution パターン | 中心の考え方 | 代表的な実装 |
|---|---|---|
| アーキテクチャ層の分離 | harness と generated code を異なる VM・異なるセキュリティ文脈に置く | Vercel の Fluid + Sandbox の 2 VM 形態;Perplexity / Bolt.new の自然な構造 |
| 認証情報の隔離 | シークレットを信頼できないドメインに入れず、egress 時にプロキシで注入 | Cloudflare の credential proxy(Worker が鍵を保持) |
| 出口制御 | firewalled runtime、localhost proxy、allowlist で外部経路を絞る | Anthropic の sandbox-runtime;OpenAI Code Interpreter の firewalled 環境 |
| 意思決定のゲート | 高リスクなツール呼び出しに明示的承認を要求 | Codex CLI の 3 段階 approval policy;Claude Code の permission prompt |
この 4 つのパターンは比較的独立しており、工学的には重ねられる。Vercel の設計は「アーキテクチャ分離 + 認証情報隔離」を同時に満たし、Anthropic の sandbox-runtime は「出口制御 + 意思決定ゲート」を同時に満たす。私たちが参照した公開資料の範囲では、これら 4 つすべてを統一された製品形態で完全に提供しているベンダーはまだ見当たらない。
その上の層、すなわち製品横断の統一ガバナンスはまったく空白だ。どの agent 製品も独自の policy 形式を定義し、独自の audit ログを持っている。開発者が Claude Code、Cursor、Aider を同時に使うと、3 セットの policy を設定し、3 つの audit log を見ることになる。モデルベンダーの商業的境界が自社製品内に閉じる構造で、この空白はサードパーティ、オープン標準、エンタープライズガバナンス層が先に埋める可能性が高い。
次の競争はどこで起きるか
私たちは次の競争の焦点が「単一の隔離プリミティブの強さ比べ」になるとは考えていない。Firecracker、gVisor、V8 isolate のような基礎インフラはすでに成熟しているからだ。私たちは競争がより構造的な論点に移ると見ている:agent 制御ループはコード実行と信頼ドメインを共有すべきか、多コンポーネント下での出口制御はどう設計するか、製品横断の統一 policy と audit 標準が実際に出てくるかどうか。