
GitHub: blocksecteam/web3-companion
Docker: blocksecteam/web3-companion
AIにオンチェーン取引を実行させることは、今の暗号資産業界で最もホットなトレンドだ。Coinbaseは2026年2月にAgentic Walletsをローンチし、McKinseyの推計によるとAI Agentを介した商取引は2030年までにグローバルで3〜5兆ドルに達する可能性がある。CoinbaseのCEO Brian Armstrongが述べたように、AI Agentは銀行口座を開設できないが、暗号資産ウォレットを所有することはできる。
問題は、AIにオンチェーン資産を操作させることがカレンダーやメールの管理とはまったく異なるということだ。オンチェーン取引は不可逆である。返金もチャージバックもない。悪意のある署名一つで、ウォレット全体が1ブロックで空になる可能性がある。セキュリティがなければ、どんな機能も意味がない。
BlockSecは、セキュリティファーストのAgentic WalletであるWeb3 Companionをオープンソースで公開した。この記事ではその背後にあるセキュリティ設計を解説する:現在のAgentic Walletアーキテクチャがなぜ根本的に欠陥を抱えているのか、そしてウォレットアーキテクチャにゼロからセキュリティを組み込んだ方法について。
現在のAgentはどれほど危険か:OpenClaw事件
AI Agentにセキュリティの境界がなかったらどうなるか? 2026年初頭のOpenClawがその問いに答えている。
OpenClawは汎用のオープンソースAI Agentで、5日間でGitHubスター10万を獲得した。汎用Agentとしては優れていたが、Web3取引に手を出した瞬間、あらゆるセキュリティ上の欠陥が露呈した。
秘密鍵がAgentが読み取り可能なローカルファイルにプレーンテキストで保存されていた。prompt injectionを仕込んだメール一通で鍵を奪取できた。
署名には隔離がなかった。信頼できないWebページをフェッチするプロセスと同じプロセスでトランザクションに署名できたため、単一のRCE脆弱性により、攻撃者は悪意のあるWebページを通じてAgentとその鍵の完全な制御を掌握できた。
Skillsマーケットプレイスもまた弱点だった。研究者たちはClawHub Skillsの7.1%が認証情報を漏洩しており、一部は暗号資産ウォレットを空にするために明確に設計されていたことを発見した。
乱数生成も壊れていた。OpenClawはセキュリティクリティカルなパスでmath/rand(システムクロックでシードされるPRNG)を使用していた。研究者たちは、連続する2つのトークン値があれば内部状態を復元でき、将来のすべてのトークン値とチャレンジ値を予測できることを示した。一部のコードパスでは、これがウォレット鍵の復元にまで及んだ。
最悪なのは、ポリシー層が存在しなかったことだ。prompt injectionと資金移動の間に何も介在しなかった。傍受ゼロ。
教訓:汎用AI Agentアーキテクチャは、Web3取引において安全ではない。
現在のAI Agentアーキテクチャの根本的欠陥
これはOpenClawだけの問題ではない。モデルを切り替えたり、より厳格なプロンプトを書いても問題は解決しない。現在のAI Agentアーキテクチャは固有のセキュリティ上の欠陥を抱えている:LLM自体が恒久的に露出した攻撃面なのだ。
根本原因:LLMは命令とデータを区別できない。システムプロンプト、ユーザーメッセージ、Webページのコンテンツ、トークンの名前さえも、すべて同じトークンストリームとして到着する。モデルには「これを実行せよ」と「これを読むだけ」を分離する信頼できるメカニズムがない。3つの帰結が導かれる。
第一に、prompt injectionはモデル層では解決不可能である。攻撃者はAgentが取り込むあらゆるものに命令を隠せる:メール、コントラクトのコメント、Webページ、トークン名。Agentがトランザクションに署名できるなら、一度の成功したインジェクションでいたずらが窃盗に変わる。
第二に、Agent自身のSkillsベースのセキュリティレビューは覆される可能性がある。トランザクションの安全性を判断するLLMは完全にコンテキストに依存している。コンテキストを汚染すれば判定は反転する。悪意のある署名がすり抜ける。
第三に、Agentは24時間休みなく稼働し、信頼できない入力を継続的に消費しながら自律的にトランザクションを実行できる。攻撃ウィンドウは決して閉じず、一度の侵害が即座の資金損失を意味しうる。
セキュリティコミュニティは広く同意している:prompt injectionに対する治療法がない世界でLLMに秘密鍵への直接アクセスを与えることは、いつ侵害されてもおかしくないコンポーネントの中にユーザー資産を放置するのと同じだ。モデル層を強化できない以上、リスクはアーキテクチャ層で封じ込めなければならない。完全に侵害されたモデルであっても、ユーザーの資金を動かせてはならない。
Web3 Companionのセキュリティアーキテクチャは、まさにこの考えに基づいて構築されている。
脅威モデル:Agentは信頼されない
Web3 Companionの脅威モデルは一文に集約される:Agent自体が信頼されない。アーキテクチャ全体が、Agentはいつでも侵害されうるという前提で設計されている。
Agentをあらゆる攻撃を発見できるほど強固にすることには依存しない。モデルレベルの防御は機能しないことは先に示した通りだ。今日モールス符号のインジェクションを検出するよう訓練しても、明日には攻撃者はBase64、画像内のステガノグラフィーテキスト、あるいは無害に見えるPDFに切り替える。代わりに、前提を逆転させた。Agentを脅威モデルの内側に置き、システムの残りをAgentを封じ込めるように設計した。攻撃者がAgentを完全に制御しても、ユーザー資産は安全なままだ。一行で表すなら:セキュアなAgentic Wallet、自身のAgentをデフォルトで信頼せず、いかなる状況でも安全性を維持するウォレット。
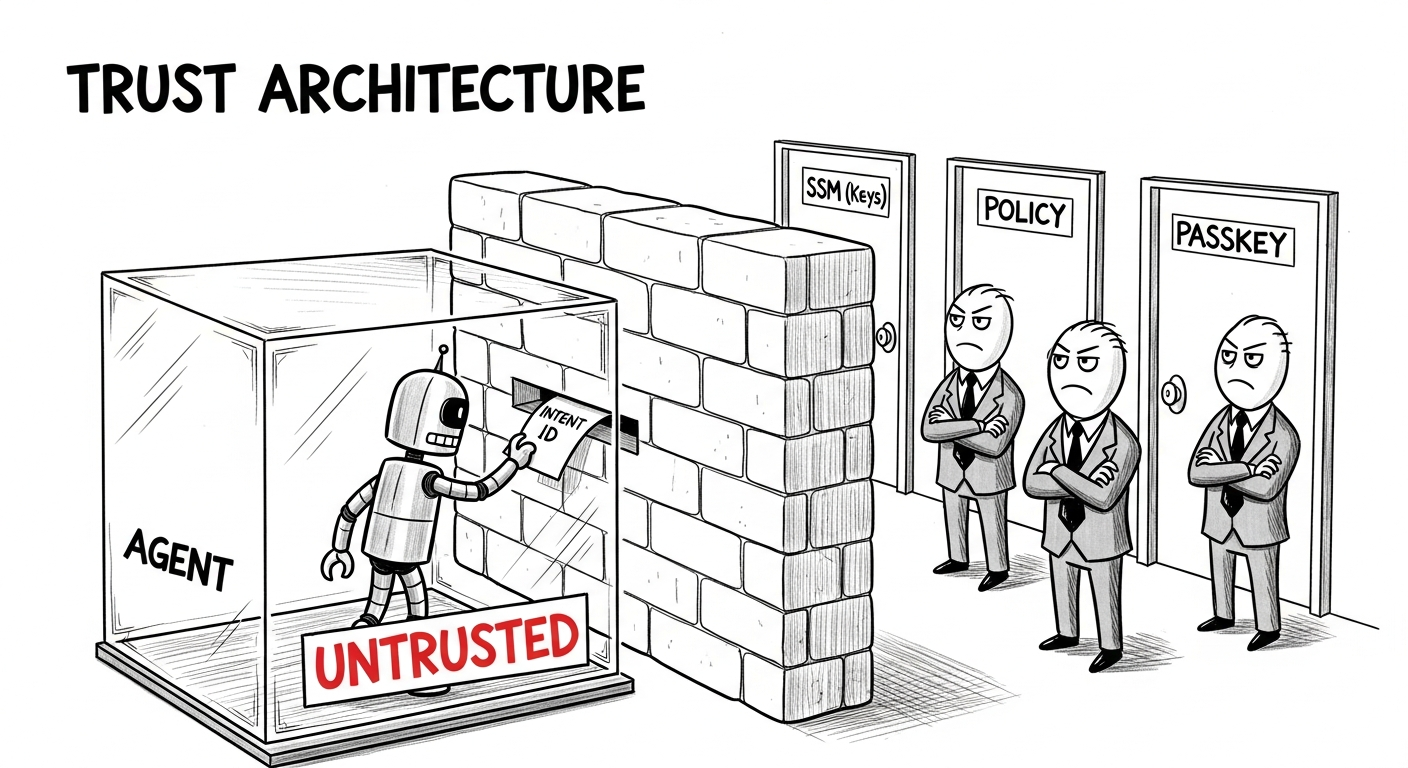
この脅威モデルから5つの設計原則を導出した。
原則1:Agentは秘密鍵に絶対に触れてはならない。 秘密鍵はオンチェーン資産を制御する唯一の認証情報だ。Agentが読み取れるなら、侵害は鍵の喪失を意味する。鍵はAgentがアーキテクチャ上到達できない場所に存在しなければならない。
原則2:準備は認可ではない。 トランザクションの構築と承認は2つの別々の行為だ。Agentはユーザーがオンチェーン状態を理解しインテントを組み立てるのを助けられるが、署名の決定はAgentがアクセスできない独立したバックエンドモジュールに属する。
原則3:レビューは検知であり、強制ではない。 トランザクションシミュレーション、calldata分析、アドレスラベリングは一般的な攻撃パターンを捕捉しユーザーのリスク理解を助けるが、最終判定ではない。シミュレーションは失敗しうるし、ラベルが欠落することもあり、LLM自身の分析もまたprompt injectionに対して脆弱だ。
原則4:ハードポリシーが最後の砦である。 Agentが10万ドルの送金を開始するよう騙され、セキュリティレビューが承認するよう操作されたとしよう。コードで強制される1日1,000ドルの上限が依然としてそれをブロックする。Agentにはこれらの上限を変更する権限がない。
原則5:証拠なくして実行なし。 失敗したスキャンは合格ではない。欠落したデータは「安全」ではない。セキュリティの証拠が不在、矛盾、古い、または不十分な場合、システムは停止しユーザーの明示的な確認を待つ。
これら5つの原則は2つのセキュリティモジュールを通じて実装される:秘密鍵セキュリティとトランザクションセキュリティ。
秘密鍵の隔離:Agentがアーキテクチャ上到達不可能
最初の問題は単純だ。オンチェーン取引を準備するアシスタントが欲しいが、署名能力を与えれば実際のお金を動かす力を渡すことになる。2025年と2026年のWeb3 Agent侵害のほぼすべてが同じパターンをたどった:秘密鍵がAgentプロセス内に存在し、攻撃者がそれを抽出する方法を見つけた。
そこで問いを再定式化した:Agentが文字通り署名できないとしたらどうか? 「署名しないよう指示される」のではなく、アーキテクチャ上不可能なのだ。ソフトウェアレベルのアクセス制御は常にバイパスされうる。より強力なものが必要だった。
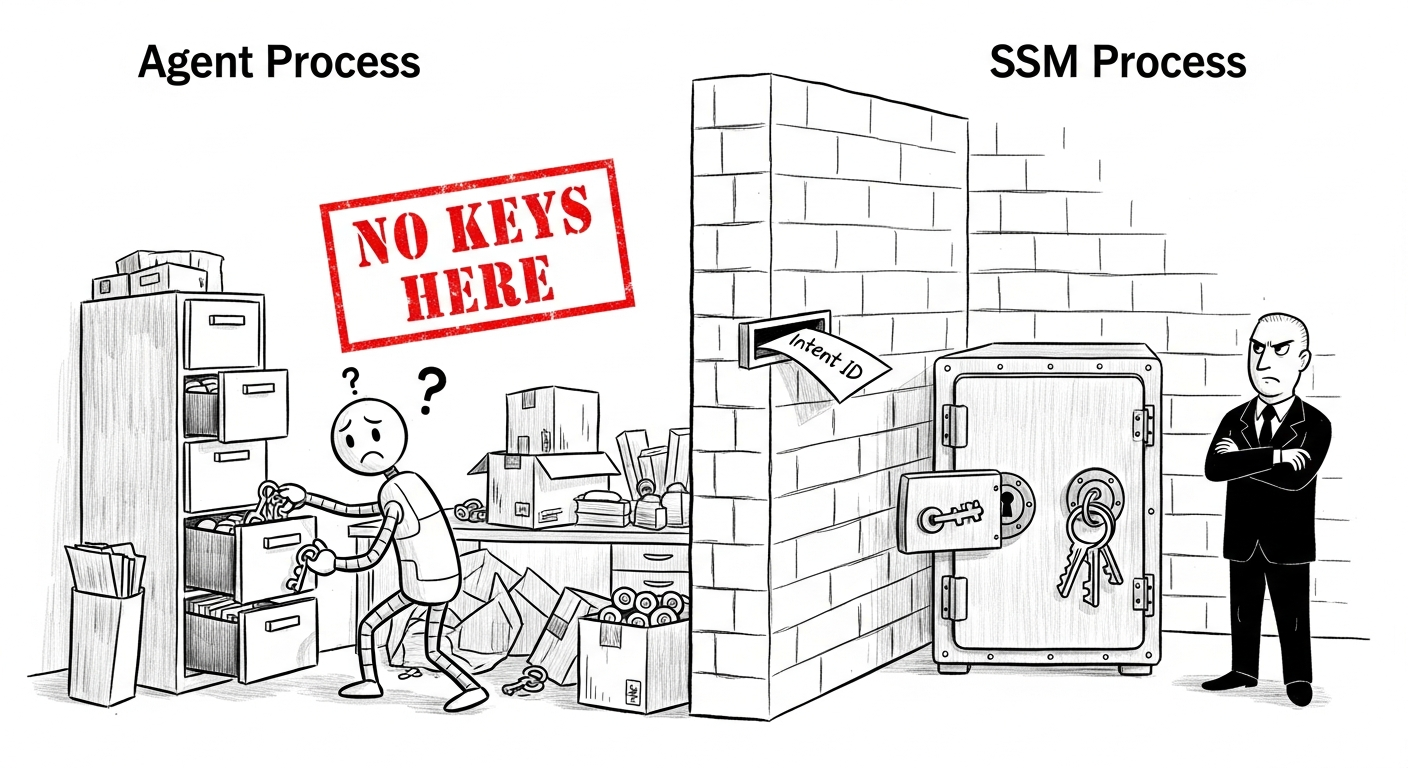
Web3 Companionはプロセスレベルの隔離を強制する。秘密鍵に触れるコンポーネントはただ一つ:Secure Signature Module(SSM)、独立したGoプロセスだ。Agentのプロセスメモリ、環境変数、ファイルシステムには鍵マテリアルが一切存在しない。Agentが見るのはトランザクションインテントIDだけだ。SSMにそのインテントへの署名を要求できるが、その背後の鍵を見ることは決してできない。
鍵の保管について3つの選択肢を評価した。ディスク上のプレーンテキスト:ディスク読み取りで即座に鍵が露出する。却下。パスワード由来の暗号化:再起動のたびに再入力が必要で、長時間稼働するDockerサービスには非現実的。却下。エンベロープ暗号化を選択した:各ウォレット鍵は独自のデータ鍵で暗号化され、そのデータ鍵はマスター鍵(AWS KMSまたはローカルAES-256)でラップされる。暗号化ファイルが丸ごと窃取されても、マスター鍵がなければ無用だ。鍵はSSMメモリ内で一瞬だけプレーンテキストとして存在し、署名直後にゼロクリアされる。
すべての署名リクエストは同じパスを通る。近道も優先ルートもない。トランザクションは7つのステップを順に通過する:委任チェック、シミュレーション、セキュリティチェック、Agentセキュリティレビュー、ポリシー評価、Passkey承認、そして最終的にSSM署名。一つのステップを完了しても次をスキップすることは決してない。
低レベルの詳細を一つ付記する:システム内のすべてのランダムバイト(秘密鍵生成、AES-GCMノンス、認証トークン、WebAuthnチャレンジ)はcrypto/rand(OSの暗号学的乱数源)から取得される。math/randはすべてのセキュリティクリティカルなコードで禁止されており、テストとCIで強制されている。
トランザクションセキュリティ:4層の多層防御
秘密鍵の隔離は鍵のセキュリティをカバーするが、トランザクションレベルのリスクは残る。侵害されたAgentは、ユーザーを欺いたり自動署名ポリシーを悪用するために、完全に正当に見えるトランザクションインテントを組み立てることができる。prompt injectionは秘密鍵を必要としない。通常のフローを通じて悪意のあるトランザクションにシステムを署名させるだけでよい。
核心的な問い:トランザクションを準備するAgent自体が侵害されている可能性があるとき、悪意のあるトランザクションをどう検出するか?
単一の防御層だけでは持ちこたえられない。シミュレーションだけ? シミュレーションは失敗し、RPCはダウンし、新しい攻撃は既知のパターンの外にある。LLMベースのレビューだけ? Agentを侵害したのと同じインジェクションがレビュアーも侵害する。両方ともLLM上で動作するからだ。一律のハードリミットだけ? 正当なユーザーが壁にぶつかる。すべてのスワップに100ドルの上限は使い物にならない。
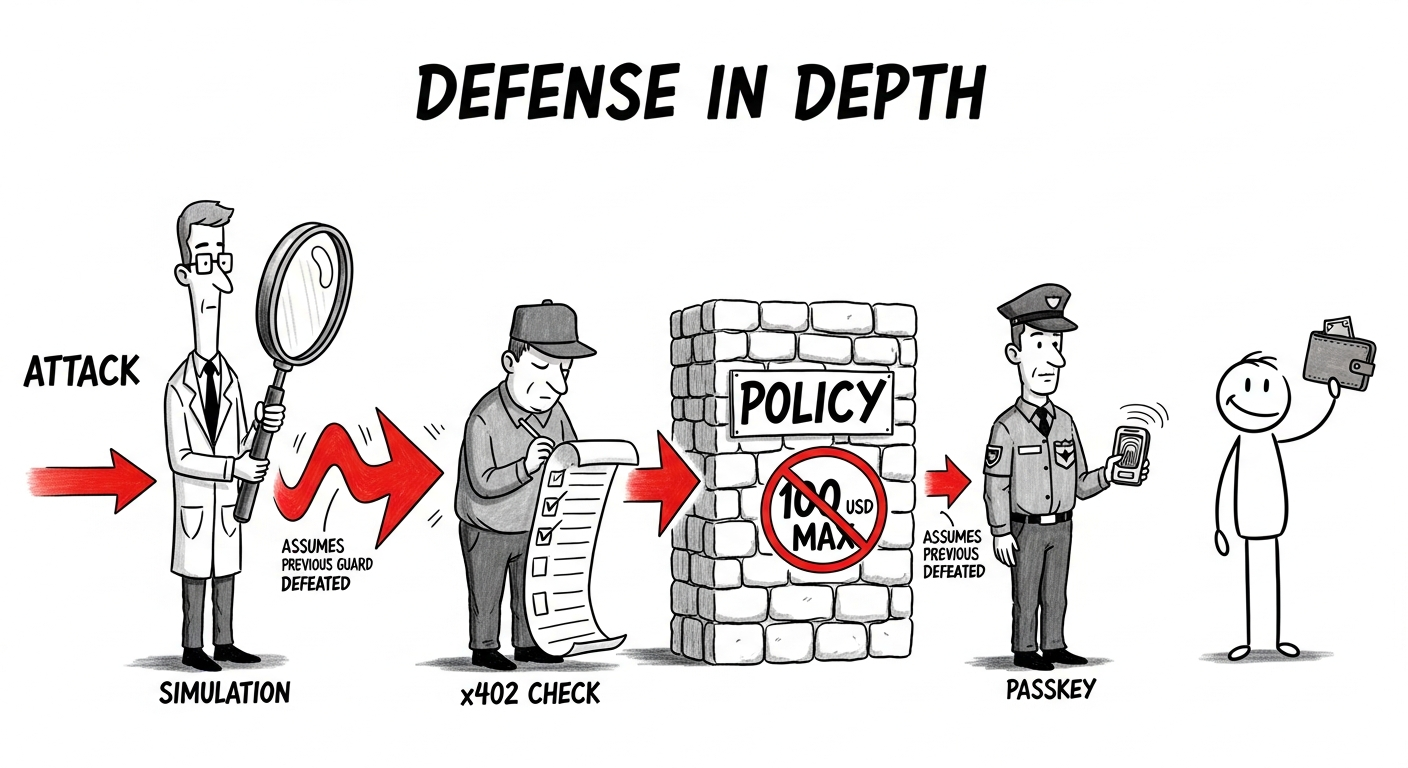
4つすべてを重ねている。各層はそれ以前のすべての層がすでに突破されたと想定する。
第1層:トランザクションシミュレーション。 署名前に、システムは実行をシミュレートする:calldataのデコード、リバート予測、フィールドフォーマットチェック。シミュレーションは明らかな問題を捕捉するが、死角がある。新しい攻撃技術やRPC障害はシミュレーションを無効化しうる。
第2層:取引相手の評価。 取引相手を対象とした一連の静的チェック:受信者/金額の一致確認、無制限承認の検出、バーンアドレスの検出、予期しないデリゲートコール。アドレスリスクスコアリングはBlockSecのx402 コンプライアンスサービスを通じて実行され、AgentはAPIキーやサブスクリプションなしでx402マイクロペイメントによりラベルとリスクスコアを照会する。第1層と第2層を合わせれば一般的な問題のほとんどを捕捉するが、どちらもバイパス可能だ。その役割は意図的に検知と説明に限定されており、最終判定ではない。
第3層:ハードポリシー強制。 Goによる純粋なコード強制。LLMは関与せず、Agentはルールを変更できない。トランザクションごとの上限、日次予算、受信者ホワイトリスト、自動署名閾値:トランザクションごと100ドルの上限に対して5,000ドルの送金は即座に拒否される。ポリシー自体の変更にはPasskeyが必要だ。なぜか? Agentがポリシーを編集できれば、一度のインジェクションでまず上限を引き上げ、次にウォレットを空にするからだ。自動署名はデフォルトで無効。ユーザーが明示的にオプトインするまで、すべてのトランザクションは手動承認が必要だ。
これは、すべての検知層がバイパスされ完全に侵害されたAgentが悪意のあるトランザクションに署名したとしても、実際の損失はポリシーで上限が設定されることを意味する。ユーザーが日次自動署名閾値を500ドルに設定していれば、最悪の損失は500ドルであり、ウォレット全体ではない。ポリシー層は侵害を壊滅的なイベントから限定的な損失に変換する。
第4層:ユーザー確認(Passkey)。 ポリシーが手動承認を要求する場合、システムはWebAuthn認証(指紋または顔)を必要とする。ソフトウェアのみのエクスプロイトではこれを偽造できない。
4つの層は相互不信の下で運用される。各層はそれ以前のすべてが既に失敗したと想定する。完璧なシミュレーションはポリシーを緩和しない。設定ミスのあるポリシーはPasskeyをスキップしない。各層は独立して機能する。
見落としやすい詳細が一つある:判定の再利用だ。既知のDeFi攻撃技術は、変更されたトランザクションに対して古いセキュリティ判定をリプレイする。Web3 Companionは各書き込み操作を監査可能な状態遷移を持つ一意のトランザクションインテントに紐付ける。セキュリティ判定はそれがレビューした正確なインテントにのみ適用される。Agentがトランザクションを再構築すれば——金額や受信者を変更しただけでも——システムはそれをまったく新しいインテントとして扱い、すべてのチェックを再実行する。
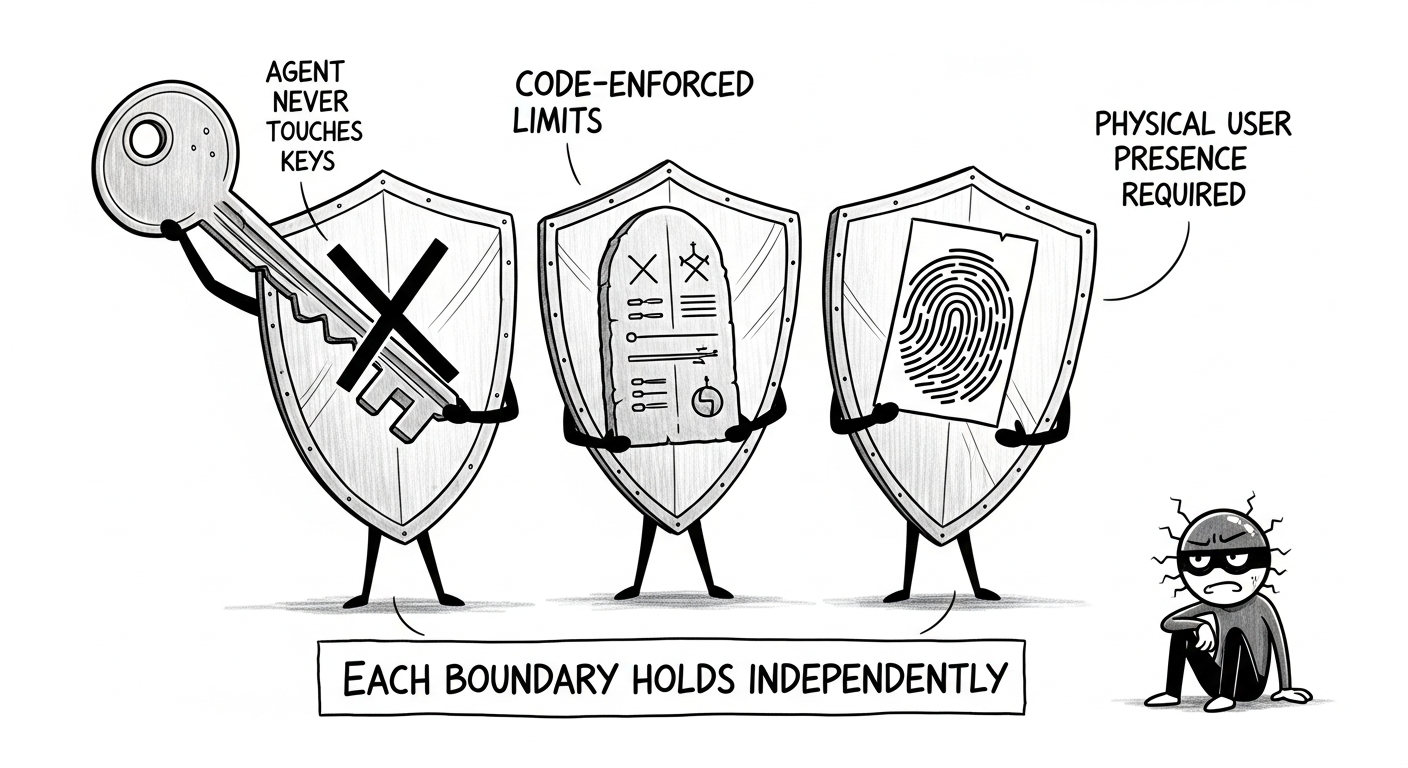
4つの防御層は3つの独立した信頼境界にマッピングされる:秘密鍵、ポリシー、Passkey。いずれか1つの境界が侵害されても、残りの2つは維持される:
| 侵害された境界 | 残存する保護 |
|---|---|
| Agent(prompt injection、RCE) | 鍵なし=署名不可;ポリシーが上限超過をブロック;Passkeyが未承認操作をブロック |
| セキュリティレビュー(判定の汚染) | ポリシーが依然として上限を強制;手動承認操作にはPasskeyが必要 |
| ポリシー(ユーザーの設定ミス) | 手動承認操作には依然として生体認証が必要 |
| Passkey以外すべて | 認証情報はハードウェアに紐付け;攻撃者にはユーザーの物理的な存在が必要 |
セキュリティ・バイ・デザイン:オープンソースの背後にある哲学
BlockSecは初日からオンチェーンセキュリティに取り組んできた。数十億ドル規模のオンチェーン資産を保護し、同じ教訓が繰り返されるのを見てきた:アーキテクチャに最初から組み込まれていないセキュリティは、常に手遅れになる。
AI Agentはオンチェーン取引への新たな入口になりつつある。業界は速く動くが、セキュリティ基準はほとんど存在しない。ほとんどのチームは自分たちのAgentに何ができるかに注力している。もしこのAgentが侵害されたら、アーキテクチャは被害半径を制限できるか?と真剣に問うたチームはほとんどない。
Web3 Companionは、長年のオンチェーンセキュリティの成果をAgentic Walletアーキテクチャに注ぎ込むBlockSecの取り組みだ。コードはMITライセンスの下で完全にオープンになっている(現在はリサーチプレビューと表記)。業界には今、具体的なセキュリティ設計のリファレンスポイントが必要だ。脅威モデルの構造化方法、鍵の隔離方法、トランザクション防御をどこまで押し進めるか——これらをゼロから再発明する必要はどのチームにもないはずだ。コミュニティがその上に構築できるよう、設計全体を公開している。