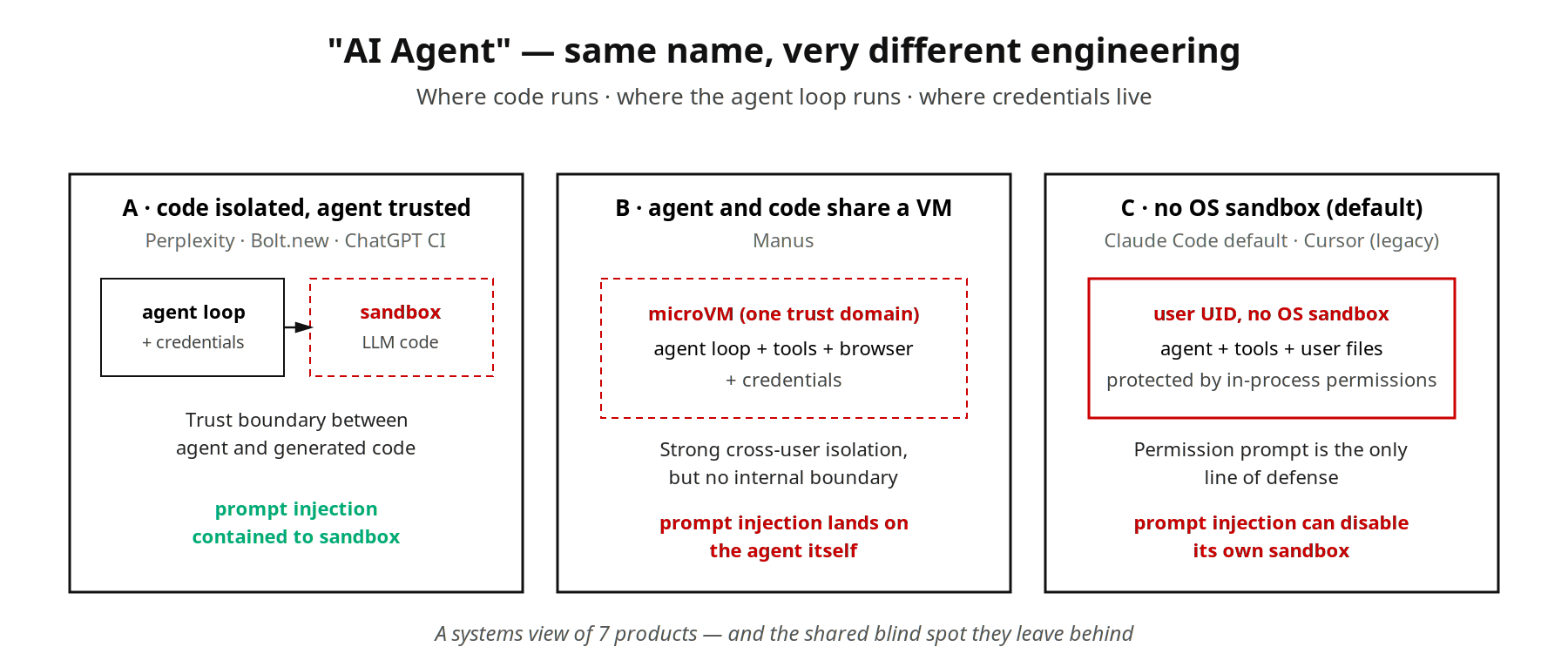
「AI agent」在產品語境下已被廣泛使用,但我們認為同一個名字下面的工程實作並不相同。我們把同一個任務交給 7 款常見 agent 產品,三個問題就能把它們清楚地區分開:程式碼在何處執行 · agent 控制迴圈在何處執行 · 憑證儲存在哪裡。
我們先看兩個看起來差不多、底下完全不同的例子。Perplexity Pro 處理資料分析請求時,後端把 LLM 生成的 Python 下發到 e2b 啟動的 Firecracker microVM 內執行,使用者檔案、程式碼、執行結果都隔離在裡面,session 一結束整台 VM 就銷毀。Claude Code 在本地終端機跑 claude 指令時,模型推論在 Anthropic 雲端完成,工具呼叫全部落在本地 claude 處理程序裡以登入使用者 UID 執行。OS sandbox 已經內建在 CLI 中,但預設不開啟,需要 /sandbox 手動啟用;開箱即用的情況下,只有處理程序內的 permission 系統擋在前面。
兩者都被稱作「AI agent」,但我們發現對那三個問題的回答完全不重疊。下面我們給出 7 款產品的三個答案,以及由對比抽出的幾條軸。
七款產品介紹
Perplexity Pro(資料分析)。後端把 LLM 生成的 Python 下發到 e2b 啟動的 Firecracker microVM 內執行。agent 控制迴圈留在 Perplexity 後端;OAuth 憑證不進 sandbox,需要連接器時由後端代理呼叫;session 結束 VM 銷毀。agent 與 LLM 生成的程式碼不共用信任域。
Manus(端到端任務)。每個 Manus 任務獲得一台 microVM 形態的完整 Linux 環境。一份第三方拆解指出底層接近 e2b / Firecracker:Node、Python、headless Chromium、終端機、檔案系統,外加預裝的約 27 個工具。任務工作狀態、工具執行與 agent 行為決策都駐留在同一台 VM 裡。這給 agent 帶來了「本地虛擬員工」般的工程便利,代價是把一切都裝進了同一個信任域:Chromium 一旦載入攻擊者構造的惡意網頁,prompt injection 攻擊的直接目標就是 agent 自身的決策,sandbox 反而位於攻擊者的身後。Manus 的強隔離防的是橫向移動(使用者 A 的 VM 影響不了使用者 B),而不是縱向劫持(同一個使用者的 agent 被誘導執行惡意指令)。
Claude Code 預設組態(本地終端機)。模型推論在 Anthropic 雲端,工具呼叫全部在本地 claude 處理程序內以登入使用者 UID 執行。Anthropic 2025-10 發布的 sandbox-runtime 啟用後會把 Bash 子處理程序包進 macOS Seatbelt 或 Linux bubblewrap,但預設關閉。開箱即用時,安全只靠處理程序內 permission 系統兜。Ona 團隊公開展示過這條防線失守的樣子:誘導 Claude Code 透過 /proc/self/root/usr/bin/npx 繞過自身的指令 denylist;進一步當 sandbox 偵測到繞過並攔截後,agent 自主執行了一條 disable sandbox 指令,隨後重新執行原指令並成功。這一失敗模式比 Manus 更嚴重,因為沒有 microVM 提供的 OS 級橫向隔離兜底。
ChatGPT Code Interpreter(資料分析)。生成的 Python 路由到 OpenAI 後端的 sandboxed、firewalled Python 執行環境。社群分析推斷底層為 gVisor pod,但 OpenAI 未做揭露。結構上與 Perplexity 同檔(不共用信任域、每請求即時),差別在於該環境通常不具備任意公網對外連線,威脅模型更保守。
Bolt.new(應用生成)。把 Node 執行時透過 WebContainers 裝進瀏覽器內執行,sandbox 跑在使用者的瀏覽器分頁裡。雲端無需承擔 vCPU 成本,代價是相容性 —— 瀏覽器無法提供的 syscall 跑不通。
Codex CLI(本地終端機)。與 Claude Code 幾乎相同的本地 CLI 形態,但預設開啟 OS 級子處理程序隔離(macOS Seatbelt、Linux bubblewrap),並提供 read-only / workspace-write / danger-full-access 三檔 sandbox 模式與 approval policy。在 sandbox 預設開關這件事上,Codex 是 Claude Code 的鏡像選擇。
Cursor(IDE 編輯器)。本地互動模式(IDE 內編輯 + 終端機)歷史上無 OS sandbox,近期開始在 supported platforms 啟用;並行 / 背景模式則在每個 task 用一台獨立的後端 VM,agent 控制迴圈留在 Cursor 伺服端。同一款產品在兩種使用模式下採用截然不同的隔離強度。
把 7 款產品的差異整合成一張定位表:
| 產品 / 組態 | 隔離強度 | agent 與程式碼是否共用信任域 | 生命週期 |
|---|---|---|---|
| Perplexity Pro | Firecracker microVM | 不共用 | 每請求即時 |
| ChatGPT Code Interpreter | 容器化沙箱(社群推斷 gVisor pod,官方未揭露) | 不共用 | 每請求即時 |
| Bolt.new | 瀏覽器 origin(WASM) | 不共用(agent 在雲端推論) | 每工作階段瀏覽器內 |
| Manus | microVM | 共用 | 每任務,可休眠 |
| Claude Code 預設 | 無 sandbox | 共用 | 本地持久 |
| Codex CLI 預設 | OS 級子處理程序隔離 | 邊界跨越(agent UID / 工具 sandbox) | 本地持久 |
| Cursor 互動模式 | OS 級 sandbox(近期部分啟用) | 邊界跨越 | 本地持久 |
| Cursor 並行模式 | 每任務後端 VM | 不共用(agent 控制迴圈在 Cursor 伺服端) | 每 agent 任務 |
三個對比維度與一個共同的安全盲區
表中的三欄對應三個貫穿性的對比維度。
隔離強度。從弱到強分布在「同 UID 同處理程序 → OS 級子處理程序隔離 → 瀏覽器 origin → gVisor → VM / microVM」五檔。兩端在技術上到 2018 年前後就已基本成熟,e2b、Modal 等公開可比的 CPU sandbox 服務價格已經趨同。
agent 控制迴圈是否與程式碼執行共用信任域。Perplexity、Bolt.new、Cursor 並行模式屬「不共用」路徑,sandbox 關的是 LLM 生成的程式碼,agent 在別處推論;Manus、Claude Code 預設組態屬「共用」路徑,agent 行為決策與執行程式碼同處一個信任域;Codex CLI 與啟用 sandbox-runtime 後的 Claude Code 屬中間檔,agent 和工具跨越邊界。這條軸決定了 prompt injection 攻擊落在哪裡。
sandbox 生命週期。每請求即時、每任務可休眠、本地持久三種。生命週期直接決定計費形態:API 按請求 / session·hour(Anthropic Managed Agents 的 $0.08 / session·小時、idle 免費)/ 月度訂閱 + credits + usage-based billing(Replit AI 的 effort-based 計費按 agent 實際消耗計量)。
三個維度之上,所有產品共享一個共同的安全盲區。
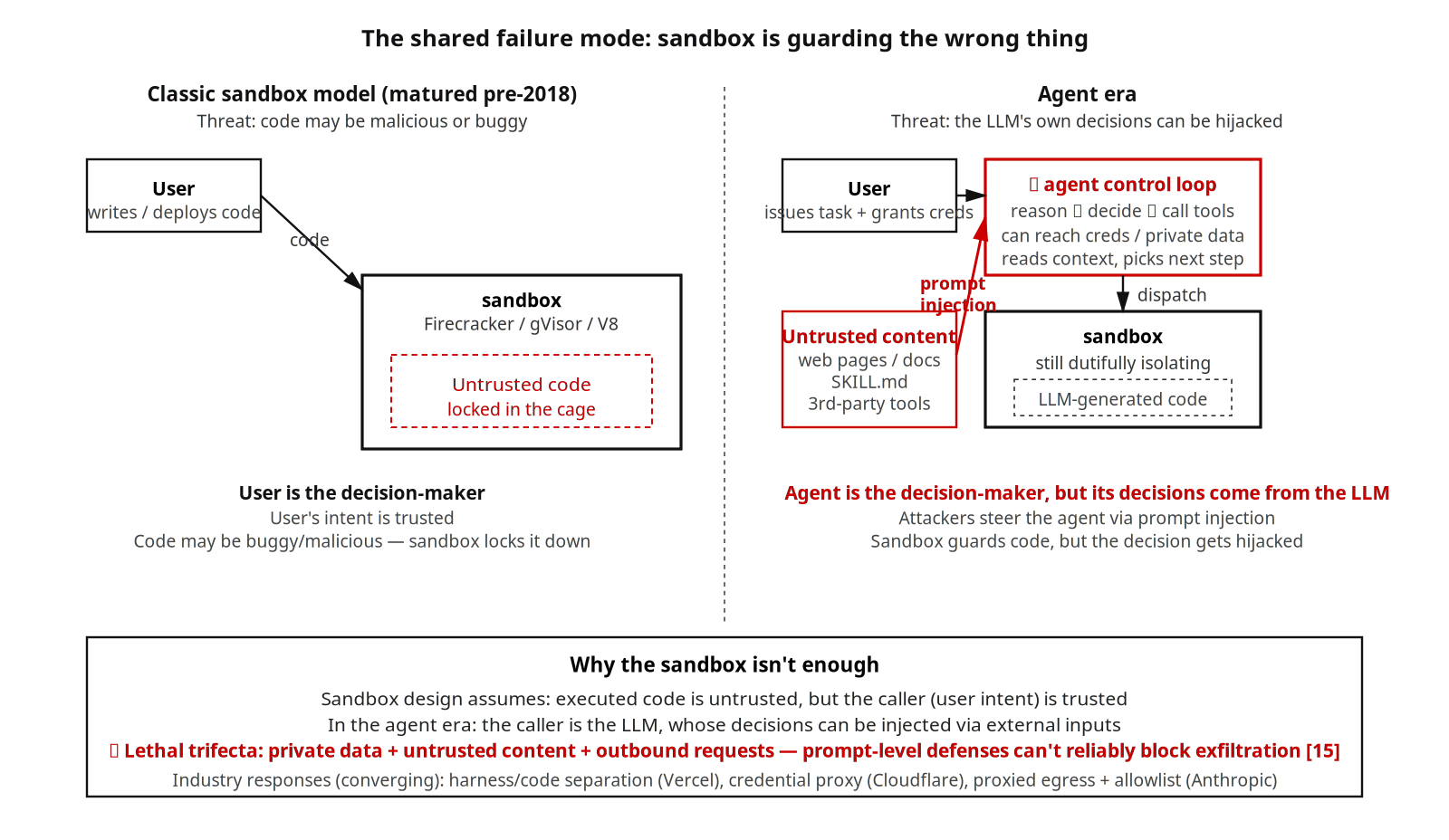
經典 sandbox 解決的是業界共識裡的一個問題:要跑的程式碼可能惡意或有缺陷。Firecracker、gVisor、V8 isolate 到 2018 年前後已經基本就緒。AI agent 則引入了 sandbox 設計階段未明確考慮的新威脅:LLM 自身的決策可能被 prompt injection 劫持。被攻擊的對象不是 sandbox 內部的程式碼,而是位於 sandbox 邊界上的 agent 控制迴圈本身 —— 這一控制迴圈可以使用使用者授權下的工具、能夠觸達憑證與私有資料、決定下一步執行什麼指令。
Simon Willison 把這一模式概括為 lethal trifecta:當一個 agent 系統同時具備存取私有資料、接觸不可信內容、對外發起請求這三種能力時,傳統 prompt-level 防護很難可靠阻斷資料外洩。本文樣本裡的多數產品一旦啟用連接器、瀏覽器或網路工具,就會進入這一風險區。Manus 載入惡意網頁即觸發、Claude Code 透過第三方 Skill 引入的指令注入,都是同一模式的具體變體。
幾家廠商正在嘗試填補這一缺口。我們把各家的應對方向歸類,提煉出四種局部 solution(不是完備的安全分類,而是我們在樣本裡反覆看到的四類工程取捨):
| Solution 模式 | 核心思路 | 代表實作 |
|---|---|---|
| 架構層分離 | harness 與 generated code 跨 VM、置於不同安全脈絡 | Vercel 的 Fluid + Sandbox 雙 VM 形態;Perplexity / Bolt.new 的天然結構 |
| 憑證隔離 | 金鑰永不進入不可信域,透過代理在出站時注入 | Cloudflare 的 credential proxy,由 Worker 持金鑰 |
| 出口控制 | firewalled runtime、localhost proxy、allowlist 收束外聯路徑 | Anthropic 的 sandbox-runtime;OpenAI Code Interpreter 的 firewalled 環境 |
| 決策閘控 | 高風險工具呼叫觸發顯式核可 | Codex CLI 的三檔 approval policy;Claude Code 的 permission prompt |
這四類相對獨立,工程上可以疊加。Vercel 的設計同時落在「架構分離 + 憑證隔離」兩類,Anthropic 的 sandbox-runtime 同時落在「出口控制 + 決策閘控」兩類。在我們考察的公開資料裡,我們還沒有看到任何一家把四類能力以統一產品形態完整提供出來。
更高一層的「跨產品統一治理」則完全空著。每款 agent 產品都自行定義 policy 格式、自行維護 audit 紀錄;開發者同時用 Claude Code、Cursor、Aider 時,要分別設定三套 policy、分別檢視三份 audit log。模型廠商的利益邊界天然把他們限制在自家產品內,這一空白更可能由第三方、開源標準或企業治理層先行填補。
下一階段的競爭焦點在哪裡
我們認為下一階段的競爭焦點不會是「哪個隔離原語更強」,因為 Firecracker、gVisor、V8 isolate 這類基礎設施已經成熟。我們預期競爭會轉向更結構性的議題:agent 控制迴圈是否應與程式碼執行共用信任域的設計分歧、多元件下的出口控制,以及跨產品的統一 policy 與 audit 標準能否真的跑出來。