
GitHub: blocksecteam/web3-companion
Docker: blocksecteam/web3-companion
讓 AI 替用戶執行鏈上交易,是當前加密貨幣領域最火熱的趨勢。Coinbase 於 2026 年 2 月推出了 Agentic Wallets,麥肯錫估計 AI Agent 驅動的商業規模到 2030 年將達到全球 3 至 5 兆美元。正如 Coinbase 執行長 Brian Armstrong 所言:AI Agent 無法開設銀行帳戶,但可以擁有加密錢包。
問題在於,讓 AI 操作鏈上資產與讓它管理行事曆或電子郵件截然不同。鏈上交易不可逆轉,沒有退款,沒有退單。一筆惡意簽名就能在一個區塊內清空整個錢包。沒有安全,任何功能都毫無意義。
BlockSec 已開源 Web3 Companion,這是一款安全優先的 Agentic Wallet。本文將深入介紹其安全設計:為什麼當前的 Agentic Wallet 架構存在根本性缺陷,以及我們如何從底層架構開始構建安全性。
現有 Agent 有多危險:OpenClaw 事件
當 AI Agent 沒有安全邊界時會發生什麼?2026 年初的 OpenClaw 事件回答了這個問題。
OpenClaw 是一個開源的通用 AI Agent,在五天內就獲得了 10 萬個 GitHub star。作為通用 Agent 它表現出色,但一旦涉及 Web3 交易,所有安全漏洞便暴露無遺。
私鑰以明文形式存放在 Agent 可讀取的本地文件中。一封 prompt injection 電子郵件就足以竊取私鑰。
簽名沒有任何隔離。同一個進程既可以抓取不受信任的網頁,也可以簽署交易,因此一個 RCE 漏洞就能讓攻擊者透過惡意網頁完全控制 Agent 及其金鑰。
Skills 市場是另一個薄弱環節。研究人員發現 7.1% 的 ClawHub Skills 會洩露憑證,部分甚至是專門設計來盜取加密錢包的。
隨機數生成也有嚴重問題。OpenClaw 在安全關鍵路徑上使用了 math/rand——一個以系統時鐘為種子的偽隨機數生成器。研究人員證明,僅需兩個連續的 token 值就能重建內部狀態並預測所有後續的 token 和挑戰值。在某些程式碼路徑中,這甚至可以擴展到錢包金鑰恢復。
更糟糕的是,根本沒有策略層。在 prompt injection 和資金轉移之間什麼都沒有。零攔截。
結論:通用 AI Agent 架構對於 Web3 交易是不安全的。
當前 AI Agent 架構的根本缺陷
這個問題不限於 OpenClaw。更換模型或編寫更嚴格的 prompt 無法解決問題。當前的 AI Agent 架構存在固有的安全缺陷:LLM 本身就是一個永久暴露的攻擊面。
根本原因在於:LLM 無法區分指令和資料。系統 prompt、用戶訊息、網頁內容,甚至代幣名稱,都以相同的 token 流形式輸入。模型沒有可靠的機制來區分「執行這個」和「只是讀取這個」。由此產生三個後果。
第一,prompt injection 在模型層面無解。攻擊者可以在 Agent 所讀取的任何內容中隱藏指令:電子郵件、合約註釋、網頁、代幣名稱。如果 Agent 可以簽署交易,一次成功的注入就能將惡作劇變成盜竊。
第二,Agent 自身基於 Skills 的安全審查可以被顛覆。LLM 判斷交易安全性完全依賴上下文。污染上下文,判決就會翻轉。惡意簽名便能輕鬆通過審查。
第三,Agent 全天候運行,持續消費不受信任的輸入,並能自主執行交易。攻擊窗口永不關閉,一次突破就意味著立即的資金損失。
安全社區普遍認同:在 prompt injection 無法根治的前提下,讓 LLM 直接存取私鑰,等同於將用戶資產置於一個隨時可能被攻破的元件之中。既然模型層無法加固,風險就必須在架構層面加以控制。即使模型被完全攻破,也不應該能夠轉移用戶資金。
Web3 Companion 的安全架構正是基於這一理念構建的。
威脅模型:Agent 是不受信任的
Web3 Companion 的威脅模型可以用一句話概括:Agent 本身是不受信任的。整個架構假設 Agent 隨時可能被攻破。
我們並不依賴讓 Agent 足夠強大到能偵測每一次攻擊。如上所述,模型層面的防禦並不奏效。今天訓練它去偵測摩斯密碼注入,明天攻擊者就會切換到 Base64、圖片中的隱寫術文字或看似無害的 PDF。因此,我們翻轉了假設。Agent 位於威脅模型之內,系統的其餘部分被設計用來控制它。即使攻擊者完全控制了 Agent,用戶資產依然安全。一句話定位:The Secure Agentic Wallet——一個預設將自己的 Agent 視為不受信任的錢包,無論如何都保持安全。
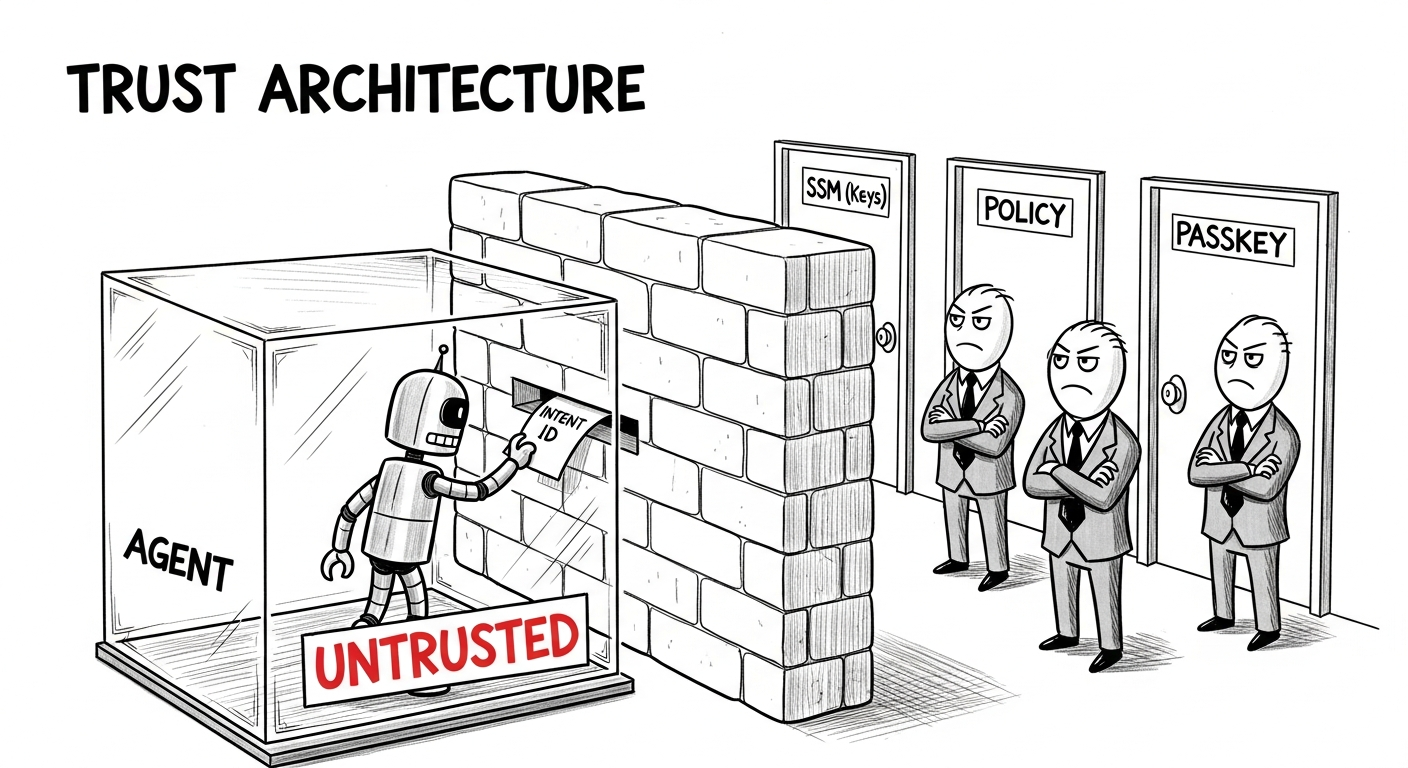
從這個威脅模型,我們推導出五項設計原則。
原則 1:Agent 絕不能碰私鑰。 私鑰是控制鏈上資產的唯一憑證。如果 Agent 能讀取它們,一次攻破就意味著金鑰丟失。金鑰必須存放在 Agent 在架構上無法觸及的地方。
原則 2:準備不等於授權。 構建交易和批准交易是兩個獨立的行為。Agent 可以幫助用戶理解鏈上狀態和組裝意圖,但簽名決策屬於 Agent 無法存取的獨立後端模組。
原則 3:審查是偵測,不是強制執行。 交易模擬、calldata 分析和地址標籤可以捕捉常見的攻擊模式並幫助用戶理解風險,但它們不是最終裁決。模擬可能失敗,標籤可能缺失,LLM 自身的分析本身也容易受到 prompt injection 的影響。
原則 4:硬性策略是最後防線。 假設 Agent 被誘騙發起一筆 10 萬美元的轉帳,且安全審查被操縱為批准它。一個程式碼強制的每日限額 1,000 美元仍然能阻擋它。Agent 無權更改這些限額。
原則 5:沒有證據,不得執行。 掃描失敗不等於通過。資料缺失不等於「安全」。當安全證據缺失、矛盾、過時或不充分時,系統會停止並等待用戶明確確認。
這五項原則通過兩個安全模組來實現:私鑰安全和交易安全。
私鑰隔離:Agent 在架構上無法觸及
第一個問題很簡單。我們希望有一個能準備鏈上交易的助手,但賦予它簽名能力就等於交出了轉移真金白銀的權力。2025 和 2026 年幾乎所有的 Web3 Agent 安全事件都遵循同樣的套路:私鑰存在於 Agent 進程中,攻擊者找到了提取它們的方法。
因此我們重新構建了問題:如果 Agent 在字面意義上無法簽名呢?不是「被告知不要」,而是架構上不可能。軟體層面的存取控制總是可以被繞過。我們需要更強的保障。
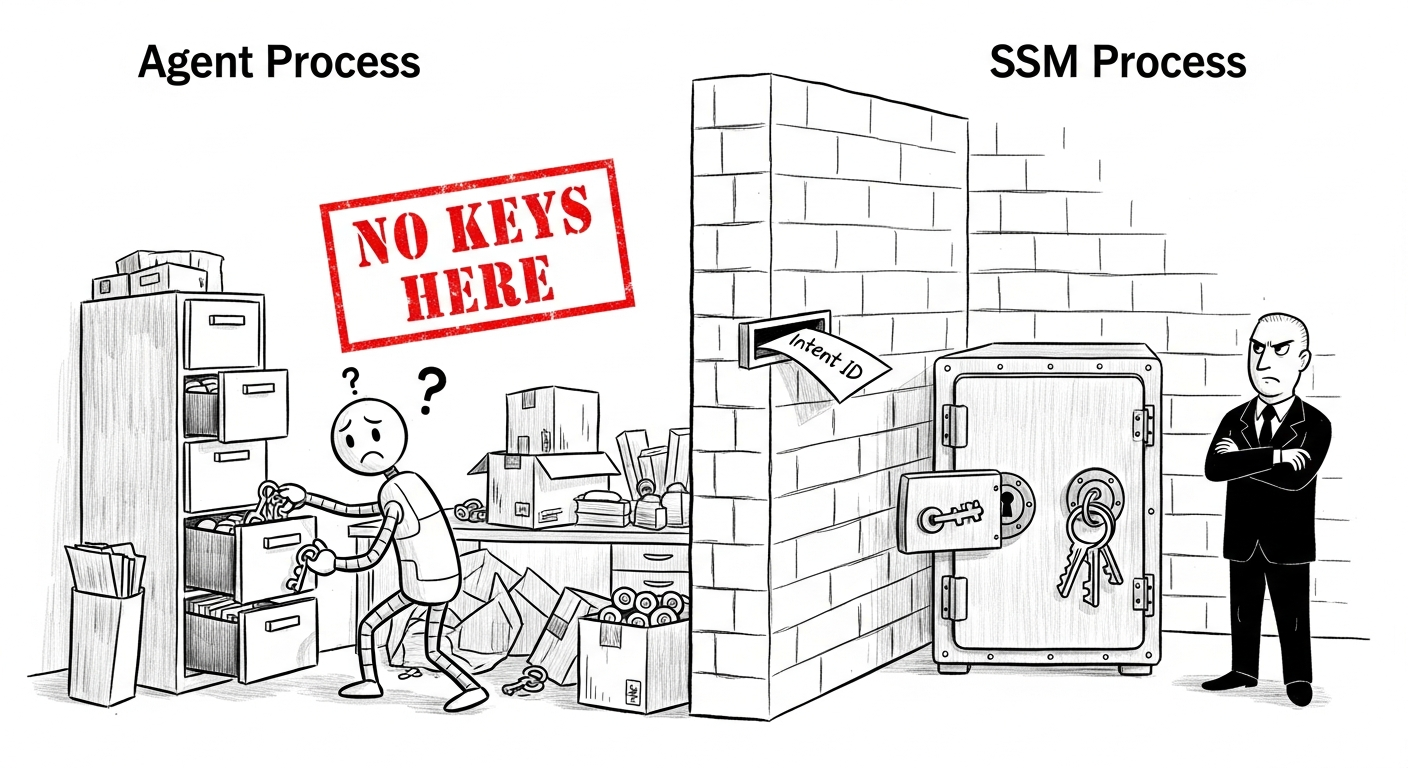
Web3 Companion 實施了進程級隔離。只有一個元件接觸私鑰:Secure Signature Module (SSM),一個獨立的 Go 進程。Agent 的進程記憶體、環境變數和文件系統不包含任何金鑰資料。Agent 能看到的只是一個交易意圖 ID。它可以請求 SSM 對該意圖簽名,但永遠無法看到背後的金鑰。
在金鑰儲存方面,我們評估了三種方案。磁碟上的明文:一次磁碟讀取就會暴露金鑰。淘汰。基於密碼的加密:每次重啟都需要重新輸入密碼,對於長時間運行的 Docker 服務不切實際。淘汰。我們選擇了信封加密:每個錢包金鑰都用自己的資料金鑰加密,而該資料金鑰又被主金鑰(AWS KMS 或本地 AES-256)包裝。即使加密文件被整體竊取,沒有主金鑰它們也毫無用處。金鑰只在 SSM 記憶體中短暫存在為明文,簽名後立即歸零。
每個簽名請求都走同一條路徑。沒有捷徑,沒有快車道。一筆交易按順序經過七個步驟:委託檢查、模擬、安全檢查、Agent 安全審查、策略評估、Passkey 批准,最後才是 SSM 簽名。完成一個步驟絕不會跳過下一個。
值得一提的底層細節是:系統中的每個隨機位元組(私鑰生成、AES-GCM nonce、身份驗證 token、WebAuthn 挑戰)都來自 crypto/rand,即作業系統的密碼學隨機源。math/rand 在所有安全關鍵程式碼中被禁止使用,並通過測試和 CI 強制執行。
交易安全:四層縱深防禦
私鑰隔離涵蓋了金鑰安全,但交易層面的風險依然存在。被攻破的 Agent 可以組裝一個看起來完全合法的交易意圖來欺騙用戶或利用自動簽名策略。prompt injection 不需要私鑰;它只需要讓系統通過正常流程簽署一筆惡意交易。
核心問題是:當準備交易的 Agent 本身可能已被攻破時,如何攔截惡意交易?
沒有任何單一防禦層能獨立支撐。僅靠模擬?模擬會失敗,RPC 可能離線,新型攻擊不在已知模式之中。僅靠 LLM 審查?攻破 Agent 的同一個注入也會攻破審查者,因為兩者都運行在 LLM 上。僅靠硬性限額?合法用戶會撞牆;每筆 swap 設定 100 美元上限根本無法使用。
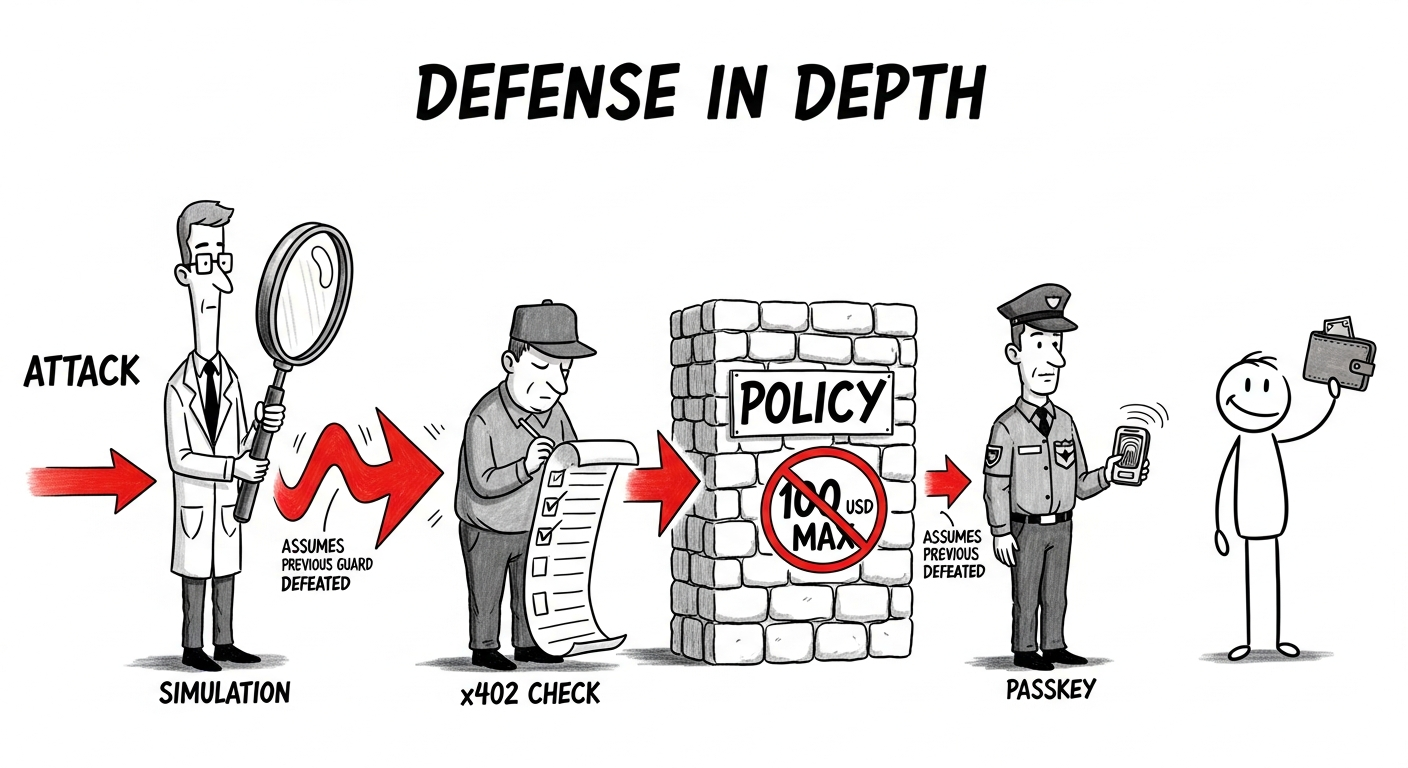
我們將四者疊加。每一層都假設前面的所有層已經被突破。
第一層:交易模擬。 在簽名之前,系統模擬執行:calldata 解碼、回滾預測、欄位格式檢查。模擬能捕捉明顯問題但存在盲區。新的攻擊技術和 RPC 故障都可能使其失效。
第二層:交易對手評估。 一系列靜態檢查針對交易對手:收款人/金額匹配、無限授權偵測、燃燒地址偵測、意外的 delegate call。地址風險評分通過 BlockSec 的 x402 合規服務運行,Agent 透過 x402 微支付查詢標籤和風險評分,無需 API 金鑰或訂閱。第一層和第二層結合可以捕捉大多數常見問題,但兩者都可以被繞過。它們的角色被刻意限定在偵測和解釋,而非最終決策。
第三層:硬性策略強制執行。 純 Go 程式碼強制執行。LLM 不參與,Agent 無法修改規則。單筆限額、每日預算、收款人白名單、自動簽名閾值:一筆 5,000 美元的轉帳遇到 100 美元的單筆限額時會被當場拒絕。更改策略本身需要 Passkey。為什麼?如果 Agent 能編輯策略,一次注入就會先提高限額,然後清空錢包。自動簽名預設關閉;在用戶明確選擇啟用之前,每筆交易都需要手動批准。
這意味著即使所有偵測層都被繞過,一個完全被攻破的 Agent 簽署了一筆惡意交易,實際損失也被策略所限制。如果用戶將每日自動簽名閾值設為 500 美元,最壞情況下的損失就是 500 美元,而非整個錢包。策略層將攻破事件從災難性事件轉變為有限損失。
第四層:用戶確認(Passkey)。 當策略要求手動批准時,系統要求 WebAuthn 驗證(指紋或人臉)。沒有任何純軟體漏洞利用可以偽造這一點。
四層之間基於互不信任運作。每一層都假設前面的一切已經失敗。完美的模擬不會放鬆策略。策略配置錯誤不會跳過 Passkey。每一層都獨立運作。
一個容易忽略的細節:判決重用。一種已知的 DeFi 攻擊技術是對修改後的交易重播舊的安全判決。Web3 Companion 將每個寫入操作綁定到一個具有可審計狀態轉換的唯一交易意圖。安全判決僅適用於它所審查的確切意圖。如果 Agent 重新構建交易——即使只是更改金額或收款人——系統會將其視為全新的意圖並重新運行所有檢查。
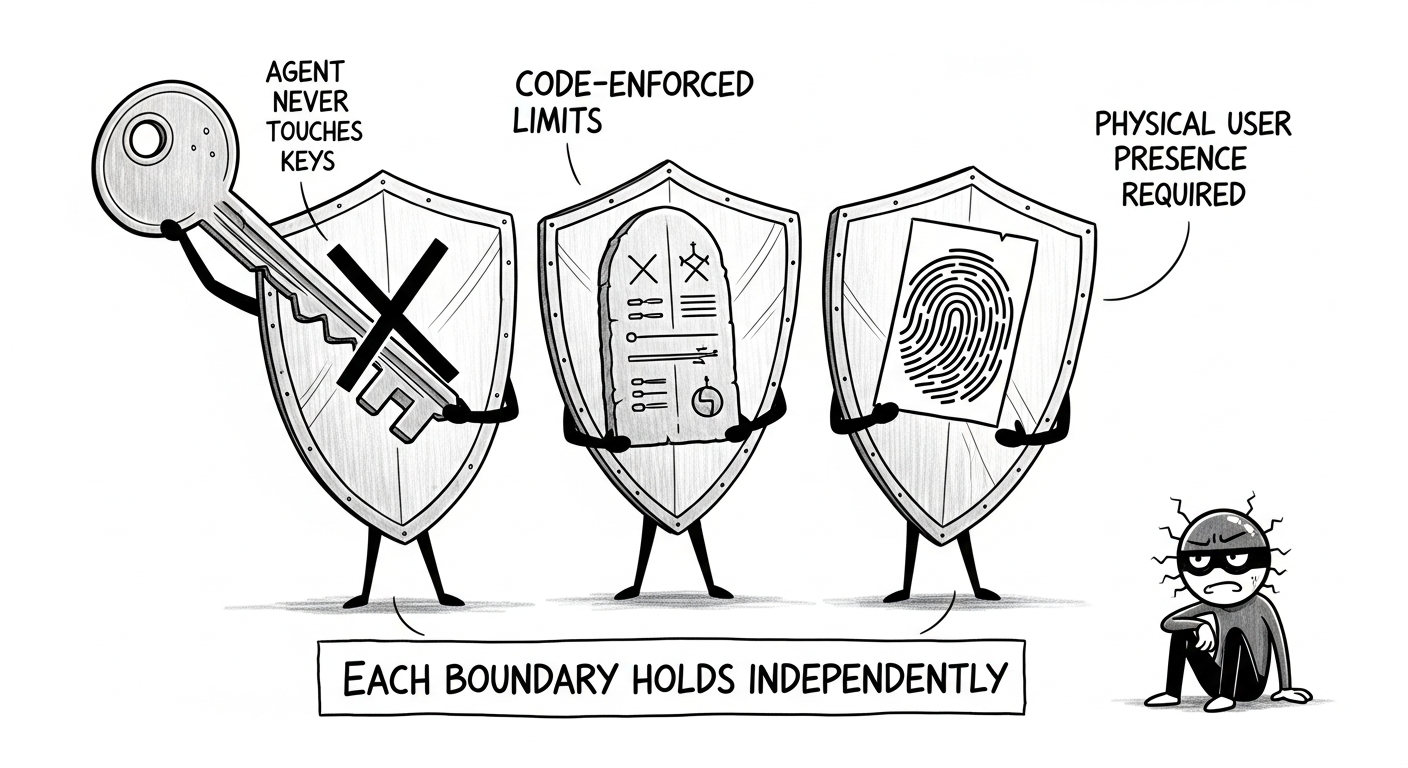
四層防禦映射到三個獨立的信任邊界:Private Key、Policy 和 Passkey。任何單一邊界被突破,其餘兩個仍然屹立:
| 被突破的邊界 | 剩餘保護 |
|---|---|
| Agent(prompt injection、RCE) | 無金鑰 = 無法簽名;策略阻擋超限交易;Passkey 阻擋未批准操作 |
| 安全審查(判決被污染) | 策略仍然強制執行限額;需手動批准的操作仍需 Passkey |
| 策略(用戶配置錯誤) | 需手動批准的操作仍需生物辨識驗證 |
| 除 Passkey 以外的一切 | 憑證與硬體綁定;攻擊者需要用戶本人在場 |
安全設計理念:開源的初衷
BlockSec 自成立之日起就專注於鏈上安全。我們已保護了數十億美元的鏈上資產,並且反覆看到同樣的教訓:不從架構階段就融入安全性,安全永遠來得太晚。
AI Agent 正在成為鏈上交易的新入口。這個領域發展迅速,但安全標準幾乎不存在。大多數團隊關注的是他們的 Agent 能做什麼。很少有團隊認真思考過:如果這個 Agent 被攻破了,架構能否限制爆炸半徑?
Web3 Companion 是 BlockSec 將多年鏈上安全經驗融入 Agentic Wallet 架構的成果。程式碼在 MIT 授權下完全開源(目前標記為研究預覽版)。產業現在就需要一個具體的安全設計參考點。如何構建威脅模型、如何隔離金鑰、交易防禦應該推進到什麼程度——沒有任何團隊應該從零開始重新發明這些。我們公開完整設計,讓社區可以在此基礎上構建。